If you only have a minute, here's what you need to know.
- Enterprise AI has an execution crisis, not an adoption crisis. 88% of organizations use AI. Fewer than 10% have scaled it beyond isolated use cases. The gap between "we're using AI" and "AI is changing how we operate" is where most programs die.
- Scaling is not a bigger pilot. Pilots prove feasibility under ideal conditions. Production requires governance, cost management, platform infrastructure, organizational redesign, and change management, all operating simultaneously. This article gives you the playbook for bridging that gap.
- The 90-day scaling sprint in this article is built to get your first AI initiative from pilot to production. It is structured around three phases: scope and commit (days 1-15), build the production path (days 15-50), and deploy with measurement (days 50-90). Each phase has specific deliverables and exit criteria.
- The five failure modes that kill scaling efforts are infrastructure gaps, data cliffs, sponsorship vacuums, adoption gaps, and governance afterthoughts. For each, this article tells you how to diagnose whether you have the problem and what to do about it before it kills momentum.
- This is the capstone article. It ties together all eight preceding dimensions into a single execution framework. If you only read one article in this series, this is the one to implement.
88% of organizations use AI. Fewer than 10% have scaled it across the enterprise.
— Stanford HAI AI Index 2026
You have read eight articles in this series. You have assessed your readiness across eight dimensions. You may have closed gaps in sponsorship, strategy, data, operating models, skills, governance, and engineering infrastructure.
None of it matters if you cannot move from pilot to production.
This article is where the series converges into a single execution framework. Not more diagnosis. Not more assessment. A playbook you can start running on Monday.
Why scaling is different from piloting
A pilot proves that a technology can solve a problem. It runs on curated data, with enthusiastic early adopters, on a developer's laptop with a $50/month API key and no governance requirements. A successful pilot has proven exactly one thing: feasibility under ideal conditions.
Here is why that pilot will not scale without deliberate infrastructure around it.
The data changes. The curated dataset you used for the demo does not represent production reality. Real data has gaps, inconsistencies, permission issues, and volume that breaks assumptions baked into the pilot. The fix is not better data cleaning. It is a continuous data readiness workstream with monitoring built in.
The costs multiply. Token consumption that was invisible at pilot scale becomes a line item that finance questions. GPU compute provisioned "just in case" sits at 5% utilization. Without the cost governance architecture from Article 8, you will not see the bill coming until it arrives.
The users change. Your pilot team was self-selected, technically curious, and forgiving of rough edges. Production users are none of those things. Without skills enablement and workflow redesign, adoption stalls at deployment.
The stakes change. A hallucination in a demo is a funny anecdote. A hallucination in production is a compliance incident. Governance that was irrelevant during the demo becomes mandatory the moment real users and real data are involved.
The infrastructure changes. Authentication, rate limiting, failover, monitoring, deployment pipelines. Each production requirement the pilot skipped must be addressed, either through shared platform infrastructure or through months of custom engineering per initiative.
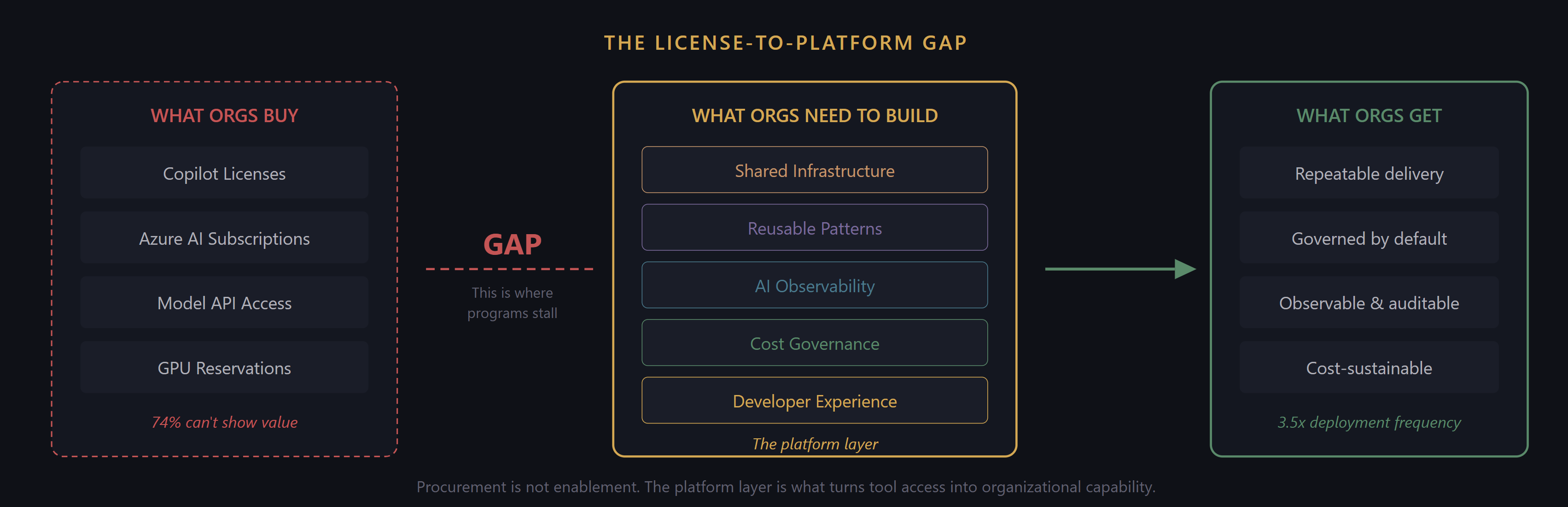
When organizations skip these prerequisites, the pilot-to-production gap becomes a cliff. The fix is not more pilots. It is building the organizational infrastructure that makes production deployment a repeatable process rather than a heroic effort.
Know where you are: four stages of AI maturity
Before you can run the scaling playbook, you need to know your starting point. MIT CISR identifies four stages, and what you should do next depends entirely on which one you are in.
Stage 1: Active. You are running pilots. Individual teams experiment with AI tools. No centralized coordination, no shared infrastructure, no governance. Most organizations are here.
What to do: Do not try to scale yet. Your job is to get one initiative to production successfully. Follow the 90-day sprint below. Resist the temptation to launch ten more pilots before the first one delivers measurable value.
Stage 2: Operational. You have one or more AI initiatives in production, but each was a custom effort. You cannot replicate the path without rebuilding everything for each initiative. The "scale" problem is now visible.
What to do: Invest in the platform layer. Convert the custom infrastructure from your first production deployment into shared services. Build golden paths from the patterns that worked. This is the highest-ROI transition in the entire journey, and it maps directly to the engineering enablement framework from Article 8.
Stage 3: Systemic. AI is integrated across multiple business functions through shared platforms and repeatable processes. New deployments are faster and cheaper than the last. The compounding effect has started.
What to do: Focus on workflow transformation, not just tool deployment. Redesign processes with AI as a first-class participant. Build feedback loops that let AI systems improve over time. Measure business outcomes, not just adoption metrics.
Stage 4: Transformational. AI reshapes strategy, not just operations. Business models and competitive positioning are built around AI-native capabilities. Very few organizations are here.
What to do: This stage is earned, not planned for. If you are executing well at Stage 3, the transformation opportunities will become visible. Trying to skip to Stage 4 from Stage 1 is how organizations burn through eight-figure budgets with nothing to show for it.
The greatest financial impact comes from the Stage 2 to Stage 3 transition. Everything in this series is designed to help you get there.

Five failure modes and how to kill them
Each of these failure modes has a diagnostic question. If you answer "yes," address it before starting the 90-day sprint.
1. The infrastructure gap
Diagnostic: Does each team that wants to deploy an AI feature have to build their own auth, monitoring, cost tracking, and deployment pipeline from scratch?
If yes, your teams are spending more time on undifferentiated infrastructure than on the AI feature itself. Every initiative takes months longer than it should, and the infrastructure is never reusable because it was built for one use case.
You know you have this problem when a Slack message like this shows up: "Hey, we just built a custom API gateway for our claims summarization bot. Anyone else done this? We also need rate limiting and cost tracking, but we have no idea where to start." Three other teams reply that they built their own. A fourth team asks if they can just copy one. Nobody's version talks to the others. That is the infrastructure gap.
What to do: Stand up a minimal shared AI platform before scaling your first initiative. You do not need the full platform from Article 8 on day one. You need three things: a shared model gateway with auth and rate limiting, a deployment pipeline with basic AI-specific checks (prompt regression, guardrail verification), and cost attribution at the team level. Build these for your first scaling initiative. The second initiative reuses them.
2. The data cliff
Diagnostic: Was your pilot built on a curated, manually cleaned dataset that does not represent the volume, quality variance, or access governance requirements of production?
If yes, the model performance your pilot demonstrated will not survive contact with real data. This is the most common source of post-deployment disappointment.
Here is how this plays out in practice. The pilot ran on 500 clean customer records, hand-selected by the data science team. In production, the system hits 2.3 million records where 18% have missing fields, 6% have conflicting entries across systems, and the address format changed three times over the past decade. The model's accuracy drops from 94% in the demo to 71% in production. The business team that signed off on the pilot feels misled. The data science team says the data was never supposed to look like this. Both are correct.
What to do: Before deploying to production, run your model against a sample of real production data, not the curated pilot set. Document every quality issue you find. Build data quality monitoring that alerts on the same issues in real time. Treat data readiness as ongoing infrastructure, not a one-time cleanup. The data readiness workstream from Article 4 gives you the six-month framework.
3. The sponsorship vacuum
Diagnostic: Will your executive sponsor still be actively involved three months after the pilot demo? Are their performance incentives tied to production outcomes, or just to pilot completion?
If your sponsor treats this as a ribbon-cutting, the initiative will stall the first time it needs an organizational blocker removed, a budget exception approved, or a cross-functional dependency prioritized. Sponsors who disappear after the demo are the single best predictor of scaling failure.
You will recognize this pattern: the SVP who championed the pilot gives a glowing demo at the board meeting, then moves on to the next initiative. Six weeks later, the engineering team needs access to a production data source owned by another business unit. They file a request. Nobody escalates it. The request sits in a queue for three weeks. By week eight, two engineers have been pulled to other projects. By week twelve, the initiative is effectively dead, listed as "in progress" on a quarterly slide deck that nobody updates.
What to do: Before starting the 90-day sprint, have an explicit conversation with your sponsor about the commitment required. They need to attend biweekly checkpoints. They need to own the escalation path for cross-functional blockers. If they cannot commit to that, find a different sponsor or pick a different initiative. The executive sponsor framework from Article 2 defines what "real" sponsorship looks like.
4. The adoption gap
Diagnostic: Is your production deployment plan focused on the technology ("deploy the model, expose the API") or on the people ("redesign the workflow, train the users, measure adoption")?
Organizations that frame AI scaling as a technology deployment achieve an 18% success rate. Those that frame it as business transformation achieve 61%. The difference is not the technology. It is whether the scaling effort owns the workflow changes, role adjustments, and success metrics that make AI productive, or whether it stops at deployment and hopes adoption follows.
Imagine you have built an AI-powered contract review tool that reduces review time by 60%. You deploy it to the legal team. Three months later, usage data shows only 4 of 22 attorneys use it regularly. The rest still email contracts to the paralegal team for manual review. When you ask why, the answer is not "the AI is bad." The answer is "nobody changed the intake process." Contracts still arrive by email. The AI tool lives on a different platform. Using it means changing a habit, and nobody made that change easy, expected, or tracked.
What to do: For every AI feature you deploy, identify the specific workflows it changes and the specific users it affects. Build a change management plan for each affected group. Define success as adoption and business impact, not as "the feature is live." The skills and literacy strategy from Article 6 shows how to enable users at each capability level.
5. The governance afterthought
Diagnostic: Will your production deployment include automated guardrails, or will governance be a manual review process bolted on after deployment?
Manual governance creates friction that kills adoption. No governance creates risk that kills the program. The organizations that scale successfully embed governance into the engineering platform so that compliance is automatic, not adversarial.
This shows up at the worst possible moment. The customer-facing chatbot has been live for six weeks. A reporter finds an example where the bot recommended a competitor's product with fabricated pricing data. Legal gets involved. The CISO gets involved. An emergency review requires every chatbot response to be pre-approved by a human for 48 hours, which creates a backlog, which makes the feature unusable, which tanks adoption, which makes the CFO question the entire AI investment. All because guardrails that should have been automated in the pipeline were deferred as "phase two."
What to do: Before production deployment, classify the initiative using the risk tiers from Article 7. For each risk classification, define the automated checks that belong in the deployment pipeline: output quality thresholds, safety classifications, human-in-the-loop triggers, and data access auditing. Build these into the platform (Article 8), not into a separate review process.

The 90-day scaling sprint
This is the execution framework. Pick your first initiative, confirm you have addressed the five failure modes above, and run this sprint.
Phase 1: Scope and commit (Days 1-15)
Select the right initiative. Not the most ambitious. The one with:
- A clear, measurable business outcome (not "explore AI possibilities")
- Available, accessible production data (not "we'll figure out data access later")
- An engaged business stakeholder who owns the workflow being changed
- The fewest integration dependencies and the lowest governance complexity
Your first scaling success needs to happen fast enough to build organizational confidence. Pick accordingly.
Write the production definition document. One page. It answers:
- Who are the production users? (Specific teams, roles, headcount)
- What are the SLAs? (Latency, availability, quality thresholds)
- What are the cost constraints? (Token budget per month, compute budget)
- What data does it access? (Sources, permissions, sensitivity classification)
- What governance requirements apply? (Risk tier, human-in-the-loop policy, compliance)
- How will success be measured? (Business KPIs, not just technical metrics)
If your team cannot agree on this document, the initiative is not ready to scale.
Lock in the sponsor. Walk the sponsor through the production definition document. Get explicit commitment to biweekly checkpoints for the full 90 days. Agree on the escalation path for blockers. If the sponsor cannot commit, stop and find one who can.
Exit criteria: Production definition document signed off. Sponsor committed. Initiative scored above 3.0 on all eight scorecard dimensions for this specific use case.
Phase 2: Build the production path (Days 15-50)
Stand up shared infrastructure. Using the five components from Article 8, build the minimum viable platform:
- Model gateway with authentication and rate limiting
- Cost attribution and alerting at the team level
- Deployment pipeline with prompt regression tests and guardrail verification
- Basic AI observability: quality metrics, latency, token consumption per request
Build these as shared services, not as one-off infrastructure for this initiative. The second initiative should be able to reuse 80% of what you build here.
Harden the data pipeline. Connect to production data sources. Build data quality monitoring. Run the model against real production data and document every issue. Address access permissions and governance requirements. Start this early. It always takes longer than expected.
Embed governance. Apply risk classification. Configure automated guardrails in the deployment pipeline. Define human-in-the-loop triggers. Ensure compliance checks run on every deployment, not as a separate review.
Prepare users. Identify every person and workflow affected by this initiative. Build role-specific training using the capability levels from Article 6. Schedule training to complete before production deployment, not after.
Exit criteria: Infrastructure deployed and tested. Data pipeline running against production data with quality monitoring. Governance checks automated in pipeline. User training scheduled.
Phase 3: Deploy and measure (Days 50-90)
Deploy to a limited production audience. Not a beta. Not a sandbox. A real deployment with real users, real data, and real monitoring. Start with a single team or business unit that participated in training.
Instrument everything from day one. Track:
- Quality metrics: relevance scores, groundedness, safety classifications
- Cost metrics: token consumption per request, per user, per day
- Adoption metrics: active users, frequency of use, task completion rates
- Business metrics: the KPIs from your production definition document
If you cannot measure it, you cannot prove it works, and you cannot improve it.
Run weekly adoption reviews. Not just usage dashboards. Talk to users. What is working? What is not? Where are they routing around the AI feature to do things the old way? Every workaround is a signal that the workflow design or the user experience needs adjustment.
Prove the business case at day 75. Connect AI system metrics to business outcomes. Present results to the sponsor. Did it deliver? Where did it fall short? What would need to change to scale to additional teams?
Document the scaling path. What did it take? What was harder than expected? What would you do differently? This document becomes the playbook for scaling the next initiative in half the time.
Plan initiative number two. If the first succeeded, you now have organizational proof that scaling works, plus reusable infrastructure, governance, and organizational muscle. Use that momentum before it fades.
Exit criteria: Production deployment live with real users. Business impact measured against KPIs. Scaling retrospective documented. Second initiative selected.

The sprint in action: a mid-market retailer
Abstract frameworks are useful. Watching one play out is better. Here is what the 90-day sprint looks like for a hypothetical mid-market retailer with 400 stores, $8B in revenue, and 12 stalled AI pilots.
The situation. The CTO's team has been running pilots for 18 months. A demand forecasting model. A customer service chatbot. An inventory optimization tool. A returns fraud detector. A product description generator. Seven others. Each has a demo. None is in production. Total investment: $4.2M. Total production value delivered: zero.
Phase 1 (Days 1-15): Picking the candidate. The team scores all 12 pilots against four criteria: measurable business outcome, data availability, stakeholder engagement, and integration complexity. The demand forecasting model wins. It has the clearest P&L impact (a 2% improvement in forecast accuracy is worth $12M annually in reduced markdowns and stockouts). The data already exists in the existing ERP and POS systems. The VP of Merchandising is the business owner, and she has been frustrated that the pilot never made it to her team's actual workflow.
The production definition document takes a week of arguments. The hardest question: what accuracy threshold counts as "good enough" to replace the existing heuristic forecasting? The team settles on matching the existing system's accuracy on 95% of SKUs while improving accuracy by at least 15% on the high-value 5% of SKUs that drive disproportionate margin.
Phase 2 (Days 15-50): Building the production path. Three things take longer than expected. First, connecting to the real POS data pipeline reveals that store-level data has a 4-6 hour latency that the pilot's daily batch process masked. Second, the demand forecasting model was trained on two years of data, but the merchandising team wants it to account for promotional calendars that live in a completely separate system with no API. Third, the existing forecasting system produces outputs in a specific format that feeds the replenishment system, and the AI model's output format does not match.
The team builds a shared model gateway that three other pilot teams immediately request access to. The cost attribution system reveals that the pilot was consuming $18K/month in compute, most of it wasted on redundant model retraining that could be cached. The data quality monitoring catches that 8% of stores report POS data with a one-day delay on weekends, which was silently degrading forecast accuracy for Monday replenishment decisions.
Phase 3 (Days 50-90): Deployment and proof. The model deploys to 40 stores first, with the existing forecasting system running in parallel. By week 10, the AI model outperforms the existing system on 89% of SKUs. More importantly, on the high-margin 5% of SKUs, accuracy improves by 22%, better than the 15% target. The VP of Merchandising presents the results at the quarterly business review: projected annual impact of $14.8M in reduced markdowns, with a direct attribution path from improved forecast accuracy to reduced overstock.
The scaling retrospective documents three lessons: data integration took 60% of the engineering effort (not model development), the parallel-run approach gave the business team confidence to adopt, and the shared infrastructure built for this initiative immediately unblocked two other pilots. Initiative number two, the returns fraud detector, begins the following week using the same platform.
What made it work: They did not try to scale all 12 pilots. They picked one, built it right, and used the infrastructure to accelerate the rest.
Industry scaling playbooks
The 90-day sprint is the execution engine. But the failure modes, data challenges, and governance requirements differ by industry. Here are abbreviated playbooks for three sectors where I see the most scaling activity.
Financial services
The scaling challenge: Regulatory density. Every production AI system in banking, insurance, or capital markets touches data governed by multiple overlapping frameworks. Model risk management (SR 11-7 for banks, similar NAIC guidelines for insurers) requires explainability, validation, and ongoing monitoring that most pilot teams have never dealt with.
The first initiative to scale: Document processing and extraction. Mortgage applications, insurance claims, KYC documentation. These have the highest volume of manual processing, the clearest accuracy benchmarks (human error rates are known and documented), and the most straightforward governance path because the human-in-the-loop workflow already exists.
The unique failure mode: Model risk management review. In most financial institutions, an AI system that makes or influences decisions about customers must pass through a model validation team. This team was built for statistical models with 6-12 month development cycles, not LLM-powered systems that can be deployed in weeks. If you do not engage model risk management in Phase 1, they will block your deployment in Phase 3. Bring them in early, educate them on LLM-specific evaluation methods, and build the monitoring they need into the platform from day one.
What "good" looks like at 90 days: One document processing workflow in production with automated quality monitoring, model risk management sign-off, and a governance template that the next three initiatives can reuse without starting the review process from scratch.
Retail and CPG
The scaling challenge: Velocity and variability. Retail operates on shorter cycles than most industries. Seasonal demand shifts, promotional calendars, supply chain disruptions, and consumer preference changes mean that AI models degrade faster and need more frequent retraining. A model that works in Q3 may be wrong by Q4 because the underlying patterns have shifted.
The first initiative to scale: Demand forecasting or assortment optimization. These have the most direct P&L impact, the most available historical data, and the clearest comparison point (the existing heuristic or spreadsheet-based process). They also have the advantage of measurable accuracy, you can compare forecast vs. actual weekly.
The unique failure mode: Data fragmentation across channels. Retail data lives in POS systems, e-commerce platforms, loyalty programs, supplier portals, and third-party market data providers. The pilot used one or two of these. Production needs them reconciled. The typical retail AI pilot trained on clean e-commerce data fails when it encounters the 40% of revenue that comes through physical stores with different data formats, latency, and quality characteristics.
What "good" looks like at 90 days: One forecasting or optimization model in production for a defined product category or store cluster, with automated drift detection that flags when model accuracy degrades below threshold, and a retraining pipeline that can execute within the weekly planning cycle.
Healthcare
The scaling challenge: Patient safety and regulatory compliance at a level that makes financial services look relaxed. HIPAA, FDA guidance on AI/ML-based Software as a Medical Device (SaMD), and institutional review board requirements create a governance environment where "move fast and iterate" is not just inadvisable, it is potentially illegal.
The first initiative to scale: Administrative and operational AI, not clinical. Prior authorization processing, clinical documentation summarization, revenue cycle optimization, patient scheduling. These have high volume, clear ROI, and lower regulatory risk than anything that touches clinical decision-making.
The unique failure mode: The clinical vs. operational boundary. An AI system that summarizes clinical notes for administrative purposes (operational) is governed differently than an AI system that recommends treatment changes based on those same notes (clinical). The line is not always obvious, and crossing it accidentally triggers FDA classification requirements that can add 12-18 months to the deployment timeline. Define the boundary in Phase 1. Build guardrails that prevent the system from being used in ways that cross it. Document the intended use explicitly.
What "good" looks like at 90 days: One administrative workflow in production with HIPAA-compliant data handling, audit trails, and a governance package that clearly delineates operational vs. clinical use. The compliance template becomes the foundation for every subsequent initiative.
What to do this week
Count your stalled pilots. How many AI initiatives in your organization have been in pilot or PoC status for more than six months? That number, multiplied by the average engineering cost per initiative, is the price you are paying for pilot purgatory. It is also the business case for running the 90-day sprint instead of starting another pilot.
Pick your scaling candidate. Strongest business case. Most available data. Most engaged stakeholder. Fewest dependencies. Not the most exciting initiative. The one most likely to succeed first.
Run the five diagnostics. For your selected initiative, answer the five diagnostic questions from the failure modes section. Every "yes" is a blocker. Address the blockers before starting the sprint, or you will learn the same lessons the hard way.
Write the production definition. One page. Users, SLAs, cost constraints, data, governance, success metrics. If your team cannot agree on this document, you know exactly where to focus before moving forward.
This is the final article in The AI Readiness Playbook series. Over nine articles, we have covered every dimension that determines whether an organization scales AI or stalls: the scorecard that diagnoses where you stand, the sponsorship that sustains the effort, the strategic alignment that connects AI to business outcomes, the data readiness that feeds the models, the operating model that structures the work, the skills strategy that enables the people, the governance framework that protects the organization, and the engineering enablement that makes deployment repeatable.
The organizations that succeed at AI do not treat these dimensions as independent workstreams. They treat them as a system, each one enabling the others, each one necessary, none sufficient alone.
The playbook is complete. The question is execution.
Matthew Kruczek is Managing Director at EY, leading Microsoft domain initiatives within Digital Engineering. Connect with Matthew on LinkedIn to discuss AI scaling strategy and the path from pilot to production for your enterprise.
References
- Stanford HAI. "AI Index Report 2026." 88% adoption, fewer than 10% at enterprise scale. hai.stanford.edu
- MIT Sloan / NANDA. "The GenAI Divide: State of AI in Business 2025." 95% of GenAI pilots fail to deliver measurable P&L impact. fortune.com
- McKinsey. "The State of AI: Agents, Innovation, Transformation." Only 6% qualify as AI high performers. mckinsey.com
- RAND Corporation. "The Root Causes of Failure for Artificial Intelligence Projects." 80% failure rate, 34% abandoned before production. rand.org
- MIT CISR. "Enterprise AI Maturity Update." Four-stage maturity model: Active, Operational, Systemic, Transformational. cisr.mit.edu
- Pertama Partners. "AI Project Failure Statistics 2026." Infrastructure limitations in 64% of failures; cost overruns average 380%. pertamapartners.com
- BCG. "As AI Investments Surge, CEOs Take the Lead." 72% of CEOs now primary AI decision-makers. bcg.com
- Deloitte. "State of AI in the Enterprise 2026." Only 21% have mature AI governance models. deloitte.com
- Gartner. "Predicts 2025." 30% of GenAI projects abandoned after PoC by end of 2025. gartner.com
- Astrafy. "Scaling AI from Pilot Purgatory." Average enterprise wastes $15-25M annually on stalled initiatives. astrafy.io
This is Article 9 of 9 in "The AI Readiness Playbook" series, a step-by-step methodology for making your organization AI-ready.