If you only have a minute, here's what you need to know.
- Most organizations equate "engineering enablement" with buying tool licenses. GitHub Copilot seats, Azure AI subscriptions, model API access. This is procurement, not enablement. 74% of companies using AI tools cannot demonstrate tangible business value from the investment. The tools are not the problem. The absence of a platform layer underneath them is.
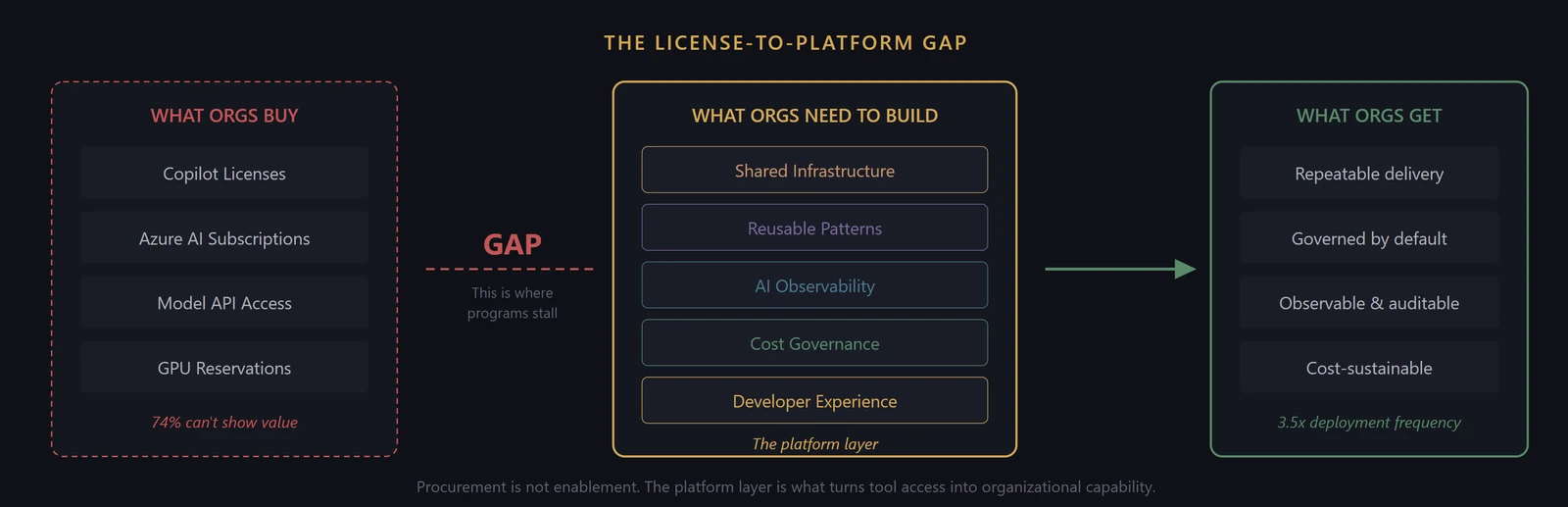
- The gap between a purchased tool and a productive team is filled by five things: shared infrastructure, reusable patterns, AI-specific observability, cost governance, and developer experience. Organizations that skip this layer end up with dozens of teams independently solving the same integration, authentication, and deployment problems, burning months of engineering time on work that should be solved once.
- Enterprise GPU fleets run at roughly 5% utilization. AI budgets have grown from $1.2M to $7M per year in two years. Without platform-level cost governance, organizations are paying for 20x the compute they actually use. FinOps for AI is not optional. It is the difference between a sustainable program and a budget crisis.
- Fewer than 30% of organizations with internal developer platforms achieve measurable productivity gains. The platforms that work share a common trait: they provide golden paths, not golden cages. Pre-built, opinionated templates that teams can adopt immediately while retaining the ability to deviate when the use case demands it.
- This article gives you the five components of engineering enablement, scoring criteria for each, and the infrastructure investments that turn governance policies from Article 7 into automated guardrails.
74% of companies using AI tools cannot show tangible business value from the investment.
Source: Stackmatix, Copilot Market Adoption Trends 2026
Your organization bought the tools. Leadership approved the budget. Every developer has a Copilot license. The AI team has Azure AI Foundry access. The data science group has model API keys.
Six months later, three teams have independently built their own RAG implementations. Two of them do not handle authentication correctly. Nobody knows what the organization is spending on inference. The governance framework from Article 7 exists on paper, but nothing in the engineering stack enforces it. Every team that wants to deploy an AI feature starts from scratch.
This is the engineering enablement gap. It is the seventh dimension on the AI Readiness Scorecard, and it is the dimension where the distance between what organizations buy and what they build is widest.
The question is not whether your engineers have access to AI tools. The question is whether your engineering organization has the platform layer that makes those tools productive, governable, and cost-effective at scale.
The license fallacy
Here is what typically happens when an enterprise decides to "enable" its engineering organization for AI.
Step one: procurement. Copilot licenses for all developers. Azure OpenAI or AWS Bedrock provisioned. Maybe a Databricks or Snowflake AI tier. The per-seat and per-token costs are budgeted. Leadership announces the investment.
Step two: expectation. Teams are expected to start building AI features. The assumption is that access to tools translates to capability, the same way providing a developer with an IDE translates to the ability to write code.
Step three: reality. Only 3.3% of potential Microsoft 365 users have signed up for paid Copilot. Among those who do, only 55% engage weekly at large enterprises. 44% of lapsed users cite distrust of AI-generated answers as the primary reason for stopping. The tools sit unused, underused, or misused.
40% of AI time savings are lost to rework. Only 14% of employees consistently achieve net-positive outcomes from AI.
Source: Workday, January 2026
The license fallacy is the belief that providing tools is the same as enabling their use. It is the engineering equivalent of the awareness ceiling from Article 6: broad access without the surrounding infrastructure to make access productive.
The missing layer is not training (covered in Article 6) or governance (covered in Article 7). It is engineering infrastructure: the platform, patterns, observability, and developer experience that sit between "we have AI tools" and "we ship AI features reliably."
Five components of engineering enablement
Engineering enablement for AI requires five distinct infrastructure investments. Most organizations have at most one or two of these in place.

The five components of engineering enablement. Most organizations have Layer 1 partially. Few have Layers 2-5.
1. Shared infrastructure
The foundation. Centralized model serving, API gateways for AI services, authentication and authorization for model access, secrets management for API keys, and standardized deployment pipelines for AI workloads.
A 2.0 looks like this: each team provisions its own Azure OpenAI instance, manages its own API keys (often in environment variables, sometimes in source control), and deploys AI features through whatever pipeline their team uses. There is no central visibility into what models are deployed, what data they access, or what they cost. When a model provider changes pricing or deprecates an endpoint, every team discovers it independently.
A 4.0 looks like this: a shared AI gateway handles authentication, rate limiting, model routing, and cost tracking for all teams. Model access is provisioned through the platform, not through individual Azure subscriptions. Deployment pipelines include AI-specific steps: model validation, prompt regression testing, and guardrail verification. Teams interact with AI services through a consistent interface regardless of the underlying provider.
The difference between 2.0 and 4.0 is not sophistication. It is whether you solve infrastructure problems once or fifty times.
2. Reusable patterns and golden paths
A golden path is a pre-built, opinionated template for a common AI workload. RAG over enterprise documents. Classification of customer support tickets. Summarization of meeting transcripts. These patterns recur across business units. Building each from scratch is engineering waste.

Golden paths eliminate the 80% of work that is identical across implementations.
A 2.0 looks like this: no shared patterns. Each team builds its own RAG pipeline, its own prompt management system, its own evaluation framework. The best patterns live in one team's repository and are unknown to everyone else. When a senior engineer leaves, their implementation leaves with them.
A 4.0 looks like this: a catalog of golden path templates covers the top 10 AI workload patterns. Each template includes the model integration, prompt management, evaluation suite, deployment config, and monitoring setup. Teams can instantiate a working RAG pipeline in hours, not weeks. The catalog is maintained by the platform team and updated as best practices evolve.
One enterprise reported 92% adoption of golden paths within 12 months of introduction, correlating with a 35% increase in feature delivery speed. The golden path does not constrain teams. It eliminates the 80% of work that is identical across implementations so teams can focus on the 20% that is unique to their use case.
3. AI-specific observability
Traditional application performance monitoring tracks latency, error rates, and throughput. These metrics are necessary but insufficient for AI workloads. An AI system can return HTTP 200 with a confident, well-formatted, completely hallucinated response. Your APM will report everything is fine.
A 2.0 looks like this: AI monitoring is limited to uptime and error rates. Nobody tracks hallucination rates, response quality, prompt drift, or token consumption at the application level. When an AI feature degrades, the team discovers it through user complaints, not monitoring.
A 4.0 looks like this: AI observability includes distributed tracing across prompts, model calls, retrieval steps, tool execution, and agent reasoning chains. Quality metrics (relevance scores, groundedness checks, safety classifications) are tracked per-request and aggregated into dashboards. Drift detection alerts when model behavior changes beyond defined thresholds. Token consumption is tracked per-feature, per-team, and per-business-unit.
By 2028, 40% of organizations deploying AI will use dedicated AI observability tools to monitor model performance.
Source: Gartner
You cannot govern what you cannot observe. The governance framework from Article 7 requires engineering telemetry to enforce. Automated guardrails depend on real-time data about what models are doing, what data they are accessing, and whether their outputs meet quality thresholds. Without AI-specific observability, governance is a policy document. With it, governance is an automated system.
4. Cost governance and FinOps
AI costs behave differently from traditional cloud costs. A single poorly constructed prompt chain can consume thousands of dollars in tokens. GPU reservations sit idle 95% of the time. Teams provision "just in case" compute without understanding unit economics.
Enterprise GPU fleets run at roughly 5% utilization, meaning 95 cents of every dollar spent on silicon is wasted.
Source: Cast AI / VentureBeat, 2026
A 2.0 looks like this: AI costs are buried in the general cloud bill. Nobody knows what inference costs per feature or per team. Budget conversations happen quarterly, by which point the spending patterns are entrenched. AI as a FinOps concern jumped from 31% to 63% in one year, but most organizations still lack the tooling to act on that concern.
A 4.0 looks like this: token consumption and compute costs are attributed to specific teams, features, and use cases. Cost budgets and alerts exist at the team level. The platform provides cost-optimized model routing (using smaller models for simple tasks, reserving expensive models for complex ones). Batch processing and caching reduce redundant inference. Teams see their AI costs in real time and own their optimization.
Average enterprise AI budgets grew from $1.2M to $7M per year between 2024 and 2026. At that growth rate, the difference between 5% and 50% GPU utilization is not a rounding error. It is the difference between a program that funds itself through value creation and one that gets cut in the next budget review. I wrote about one dimension of this problem in The Token Tax: untrained developers burning through hundreds of thousands in AI tokens because nobody built the guardrails, monitoring, or architectural patterns that make token consumption visible and manageable. The platform layer is where those guardrails live.
5. Developer experience
The last component is the one most often overlooked. If building an AI feature requires a developer to navigate three different portals, write custom integration code for each model provider, manually configure monitoring, and submit a governance review through a SharePoint form, adoption will stall regardless of how good the underlying tools are.
A 2.0 looks like this: developers figure it out themselves. Documentation is scattered across wikis, Confluence pages, and Slack threads. Getting a new AI project from "idea" to "running in a dev environment" takes two to three weeks of setup. The experience varies dramatically between teams based on who has done it before.
A 4.0 looks like this: a developer can go from "I want to build an AI feature" to "I have a running prototype with proper auth, monitoring, and cost tracking" in less than a day. A CLI or portal provides project scaffolding from golden path templates. Documentation is centralized, current, and includes working examples. The platform handles the undifferentiated heavy lifting so developers focus on business logic.
Organizations with mature platform engineering report 3.5x higher deployment frequency and 4x shorter lead times. Developer experience is not a nicety. It is the primary determinant of whether your engineering investment produces AI features or AI frustration.
The platform maturity trap
Roughly 90% of enterprises now report having some form of internal developer platform, surpassing Gartner's 2026 prediction of 80% early. But fewer than 30% achieve measurable developer productivity gains. The platforms exist. They just do not work.
The most common failure is building a platform nobody asked for. The platform team spends months building abstractions and self-service portals based on what they think developers need. When developers finally get access, the platform does not match their actual workflows, so they route around it.
The platforms that succeed start with one golden path that solves one real pain point for one team. They prove value on that narrow scope, then expand. They treat adoption as a metric, not an expectation. They invest in developer experience before investing in feature breadth.
The DORA 2025 Report found a direct correlation between internal platform quality and an organization's ability to unlock value from AI. This makes intuitive sense. AI capabilities are only as good as the engineering infrastructure that delivers them to production. Platform maturity is not separate from AI maturity. It is a prerequisite for it.
The PoC-to-production gap
Gartner predicted that 30% of generative AI projects would be abandoned after proof of concept by end of 2025. RAND Corporation puts the broader AI project failure rate at 80%, with 34% abandoned before reaching production.
The engineering enablement gap is a primary driver. A proof of concept runs on a developer's laptop with hardcoded API keys, no monitoring, no cost tracking, and manual deployment. Moving to production requires all five enablement components: shared infrastructure for reliable hosting, patterns for consistent implementation, observability for operational visibility, cost governance for sustainability, and developer experience for maintainability.
Without the platform layer, every PoC-to-production transition is a custom engineering project. Teams spend more time building the surrounding infrastructure than building the AI feature itself. The 80% failure rate is not a technology problem. It is an infrastructure problem.
Scoring 2.0 versus 4.0
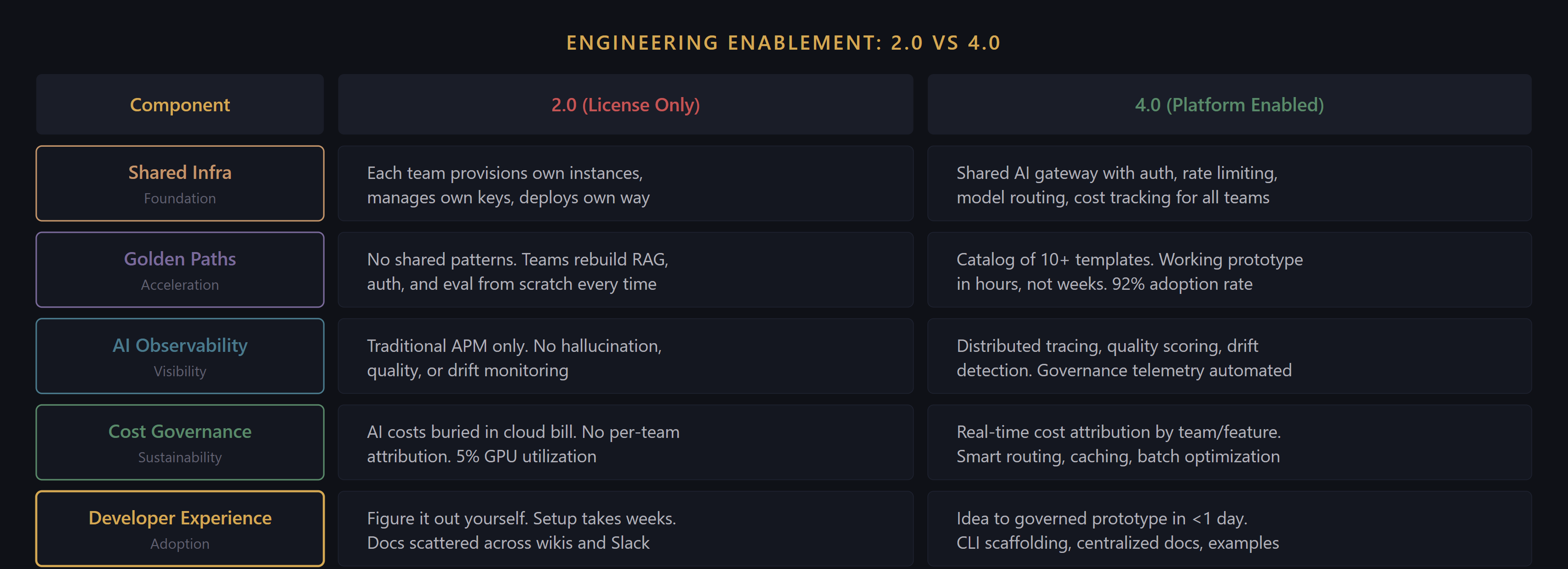
Engineering enablement scoring. The gap between 2.0 and 4.0 is a platform gap.
A 2.0 organization has purchased AI tools but not built the platform to use them effectively. Each team operates independently: provisioning their own infrastructure, building their own integrations, managing their own costs. There is no shared catalog of patterns. Observability is limited to traditional APM. Governance policies exist but nothing in the engineering stack enforces them. The PoC-to-production transition takes months and requires significant custom work for every initiative.
A 4.0 organization has an AI platform layer that makes AI development a repeatable, governed, observable, and cost-managed process. Shared infrastructure eliminates redundant work. Golden paths accelerate common workloads. AI-specific observability provides the telemetry that governance requires. Cost attribution and optimization are built into the platform. A developer can go from idea to governed prototype in days, not months.
The gap between 2.0 and 4.0 is not a tool gap. It is a platform gap: the difference between buying AI capabilities and engineering an organization that can use them.
What to do this week
Audit your redundant implementations. How many teams have independently built RAG pipelines, prompt management systems, or model integration layers? If the number is greater than two, you are paying the platform tax: engineering time spent solving problems that should be solved once. Quantify the hours. That number is the business case for shared patterns.
Map your AI cost visibility. Can you answer, right now, what your organization spent on AI inference last month, broken down by team and use case? If you cannot, you have a FinOps gap that will become a budget crisis as AI adoption scales. Start with attribution. You cannot optimize what you cannot attribute.
Measure your setup time. How long does it take a developer to go from "I want to build an AI feature" to "I have a running prototype with auth, monitoring, and cost tracking"? If the answer is weeks, your developer experience is the bottleneck. If the answer is "it depends on which team," your platform is inconsistent.
Connect your governance to your engineering stack. Take the risk classifications from Article 7 and identify which ones could be enforced through automated checks in your deployment pipeline. If the answer is "none of them," your governance framework and your engineering platform are operating in separate universes. The next step is connecting them.
The scorecard in Article 1 measures Technology and Infrastructure as a standalone dimension, but this article shows it is the connective tissue between every other dimension. The operating model from Article 5 determines who builds. The skills strategy from Article 6 determines whether they can build. The governance framework from Article 7 determines whether what they build is safe. Engineering enablement determines whether any of it is repeatable, observable, and sustainable.
The final article in this series addresses the dimension that ties everything together: scaling from pilot to production across the full organization.
References
- Stackmatix. "Copilot Market Adoption Trends 2026." 74% of AI tool buyers cannot demonstrate tangible business value. stackmatix.com
- Stackmatix. "Microsoft Copilot Adoption Statistics 2026." 44% of lapsed Copilot users cite distrust of answers as primary reason for stopping. stackmatix.com
- Alphastreet. "Microsoft's 16M Copilot Seats: Enterprise Adoption or Shelfware Risk?" Only 3.3% of potential users signed up; 55% weekly engagement at large enterprises. alphastreet.com
- Workday. "Companies Are Leaving AI Gains on the Table." 40% of AI time savings lost to rework; only 14% achieve consistent net-positive outcomes. workday.com
- Cast AI / VentureBeat. "The $401 Billion AI Infrastructure Problem." Enterprise GPU fleets at ~5% utilization. venturebeat.com
- ARK Invest. "The State of AI Infrastructure: Demand, Costs, Custom Silicon." AI FinOps concern grew from 31% to 63%; average AI budget from $1.2M to $7M. ark-invest.com
- Gartner. "40% of Organizations Deploying AI Will Use AI Observability to Monitor Model Performance by 2028." Dedicated AI observability adoption rising to 40% of organizations deploying AI by 2028. gartner.com
- Gartner. "30% of GenAI Projects Will Be Abandoned After PoC." gartner.com
- RAND Corporation. "80% of AI Projects Fail to Deliver Intended Business Value." 34% abandoned before production. pertamapartners.com
- Jellyfish. "Golden Paths in Platform Engineering." 92% golden path adoption within 12 months; 35% feature delivery speed increase. jellyfish.co
- PlatformEngineering.org. "10 Platform Engineering Predictions for 2026." 3.5x deployment frequency, 4x shorter lead times with mature platforms. platformengineering.org
- DORA. "2025 State of DevOps Report." Direct correlation between platform quality and AI value realization. dora.dev
- Kruczek, M. "The Token Tax: Why Untrained Developers Are Your Most Expensive AI Problem." matthewkruczek.ai
- Kruczek, M. "The AI Readiness Scorecard." Technology and Infrastructure as a core dimension. matthewkruczek.ai
- Kruczek, M. "Governed AI at Speed." The governance framework that engineering enablement operationalizes. matthewkruczek.ai
This is Article 8 of 9 in "The AI Readiness Playbook" series, a step-by-step methodology for making your organization AI-ready. Connect with me on LinkedIn or Substack to discuss AI platform engineering and engineering enablement strategy for your enterprise.