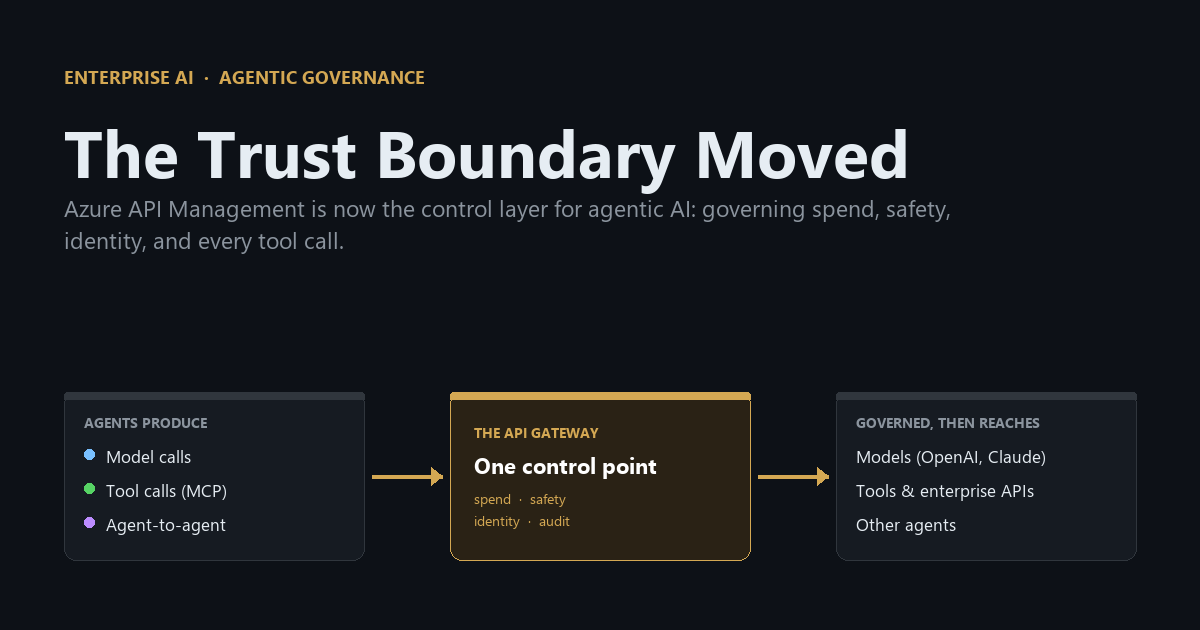
Model-level safety cannot govern agent behavior. The API gateway is the one point every model call, tool invocation, and agent-to-agent hand-off passes through, and Microsoft just turned its gateway into the place you govern all three.
If you only have a minute, here is what you need to know.
- In 2025, the AI failures that hurt companies were not wrong answers. They were agent actions: code deleted, data leaked, systems wiped. A wrong answer is a suggestion a human can ignore. A wrong action has already happened.
- You cannot fix this inside the model. Once an agent can act, the only place to control it is the one point every action passes through: the moment it reaches out to another system. That point is the API gateway.
- Azure API Management, Microsoft's gateway, now does this job. It caps spending, screens for hidden malicious instructions, avoids paying twice for the same answer, and tracks exactly which team and agent spent what.
- Over 2025 it also learned to govern the two newer kinds of agent traffic: agents using tools, and agents handing work to other agents. One gateway now sits in front of all three.
- The caveats matter. Budget caps count separately in each region, so a company-wide cap takes some math. Governing Claude needs the newer version of the product. Several of the most advanced pieces are still preview. Know what is finished and what is not before you build on it.
Why model-level safety cannot govern agent actions
For three years, the industry has poured its safety effort into the model itself: training it to refuse bad requests, filtering what it says, red-teaming it for weaknesses. That work is real and worth doing. It is also not enough for agents, for a simple reason.
Safety built into the model works on the words the model produces. But an agent's words are not what hurt you. What hurts you is what the agent does: the systems it touches, the data it moves, the actions it takes. And every one of those actions has to pass through the same chokepoint, the moment the agent reaches out to another system. A filter that reads the agent's language and approves it has no idea whether the action on the other side is allowed, affordable, pointed at the right data, or charged to the right team.
The controls that actually matter for agents, who is allowed to do what, how much they can spend, which systems they can reach, and a record of everything they did, all live at that chokepoint. They always have. That chokepoint is the API gateway. What changed in 2024 and 2025 is that Microsoft taught its gateway, Azure API Management, to understand AI traffic specifically.
Here is what a well-governed agent setup actually needs, and where each control has to live:
| What you need to control | Can the model do it? | Can the gateway do it? |
|---|---|---|
| Stop a runaway agent from blowing the budget | No | Yes, speed limits and monthly caps |
| Block a poisoned instruction before the model acts on it | Partly | Yes, screening on the way in |
| Tell which team or agent spent the money | No | Yes, tag and track every call |
| Control which tools an agent is allowed to use | No | Yes, rules per tool and per identity |
| Trace every agent action back to a name | No | Yes, one log of everything that crossed |
| Stop paying twice for the same answer | No | Yes, cache repeated questions |
The gap is structural. So is the fix: enforce at the gateway.
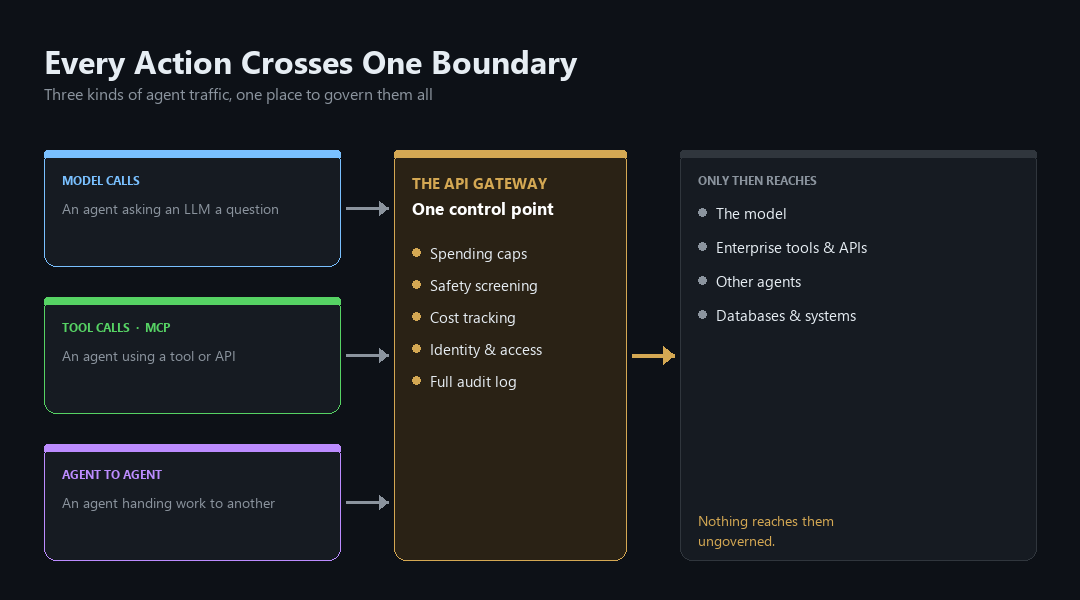
Model calls, tool calls, and agent-to-agent hand-offs all funnel through one gateway before reaching any system.
The four gateway controls that actually matter
Microsoft built a set of AI-specific controls into the gateway starting in 2024. Four of them form the core. Everything else builds on these. None of them require you to change a line of your agent's code; they sit in front of the models and do their work as traffic passes through.
1. Token limits: a spending cap with two speeds
This is the cost control. It puts a ceiling on how much an agent can spend, measured in tokens, the unit you actually get billed for, and it does it two ways at once.
The first is a speed limit: so many tokens a minute. Go too fast and the gateway tells the agent to wait a moment and try again. This stops a runaway agent from burning through your budget in a sixty-second loop.
The second is a hard budget: so many tokens a month. Hit the ceiling and the gateway stops the agent until the next month begins. This is the line finance actually cares about.
Most write-ups blur these together. They should not. One says "slow down," the other says "stop." You can set both on the same team or application, and you usually should.
Here is the part that saves real money. The gateway can measure how big a request is before it reaches the model, and turn away anything over the limit. A request that gets turned away never reaches the model, so it never lands on your bill. When an agent goes haywire and fires ten thousand requests in a minute, they pile up against the gate, not against your invoice.
One catch worth knowing up front: each copy of the gateway keeps its own count. If you run the gateway in three regions, a "one million tokens a month" limit is really a million per region, three million in total. The older request-counting limits add up across regions; this newer token limit does not. If you are setting a company-wide budget, do the multiplication before you trust the number.
2. Content safety: catching the poisoned instruction
The scariest new risk with agents is not someone typing something nasty into a chat box. It is an attacker hiding a malicious instruction inside something the agent reads on its own: a document, an email, a web page, the result of another tool. The agent picks up the hidden instruction and follows it, thinking it is part of the job.
This is exactly how the well-known Copilot attacks worked. Nobody typed anything wrong. The agent read a booby-trapped document and quietly did what the document secretly told it to do.
The content-safety check sits in front of the model and screens every request for this. It catches the obvious version, a user trying to talk the agent out of its rules, and the dangerous version, a hidden instruction buried in content the agent picked up somewhere else. Anything that trips the filter is blocked before the model ever sees it. A newer setting extends the same screening to the model's answers on the way back out. (Microsoft calls this feature Prompt Shields, if you want to look it up.)
The honest limits: it does not catch everything, it is tuned for a handful of languages so it can misfire in others, and it needs a separate Microsoft service wired up behind it. It is real protection, not a force field.
3. Semantic caching: stop paying twice for the same answer
Every time an agent asks the model a question, you pay for it. Semantic caching means the gateway remembers answers it has already paid for, and hands them back for free when the same question comes around again, even when it is worded differently.
Ask the model to "summarize this contract." Later, ask it to "give me a summary of this contract." A normal system treats those as two separate jobs and bills you twice. The gateway recognizes they mean the same thing, returns the answer it already has, and never calls the model the second time.
This matters more for agents than for people. A person asks one question and reads the answer. An agent fires off dozens or hundreds of near-identical requests in a single run: "pull the key facts from this record," then "extract the main points from this record," over and over. Same meaning, slightly different words. The cache catches every one of those repeats and stops the bill from climbing.
You decide how close a match has to be. Set it tight and only near-identical questions get a free answer. Loosen it and more questions qualify, but you risk handing back an answer that is close but not quite right. Most teams start tight and loosen carefully.
The catch the marketing skips: this needs its own piece of infrastructure, a fast in-memory cache, running alongside the gateway. It is not a checkbox. Budget for it, and weigh that cost against what you save.
4. Cost tracking: knowing who spent what
The controls above stop overspending. This one tells you where the money went.
Every time an agent calls the model, the gateway records how much it used and tags it: which team, which agent, which application. That tag is the whole game. Without it, you get one giant AI bill at the end of the month with no way to split it. With it, you can answer the question every CFO eventually asks: what did the legal team's contract-review agent cost us in May?
Azure's built-in tracking is worse than you would expect for this. It hides part of the caller's identity and scatters the records across regions, so you cannot cleanly tie spend back to a team. Routing everything through the gateway, with one identifier per application, puts the full picture in one place you can actually query. Microsoft's own guidance names this as a top reason to put the gateway in front of your models in the first place.
One thing to watch: tag by team or application, not by individual person. Tagging every single user creates so many separate counters that you can overwhelm the monitoring system and break the very dashboard you were building.
Build 2025: the gateway becomes the front door for agent tools
Here is some quick background. When an AI agent needs to do something in the real world, look up a customer, check inventory, file a ticket, it does it by calling a "tool." MCP is simply the shared standard for how agents and tools talk to each other, the way USB is the shared standard for plugging in a device. It is becoming the common language for connecting agents to enterprise systems.
At its May 2025 conference, Microsoft announced that the gateway can now sit in the middle of that conversation. This is the change that turned APIM into real agent infrastructure.
It works two ways. Either you take an API you already run and turn it into an agent tool with a switch, or you take a tool that already lives somewhere else and route it through the gateway so it finally has rules around it. Either way, the tool ends up governed.
Here is the simplest version. Say you already have an internal service that looks up a customer record. Flip on this feature and that lookup instantly becomes a tool an AI agent can use, with no new code written. The agent just sees a tool it can call. The gateway sees one more request to screen, rate-limit, and log, like everything else. The tool is governed the moment it goes live, not bolted on afterward.
This is the capability with no real equivalent in Amazon's or Kong's core products today. Agents, whether GitHub Copilot, Claude, ChatGPT Enterprise, or something your team built, reach your enterprise tools only through one governed door. The gateway checks who they are, applies the spending limits, screens for the poisoned instructions described above, and logs every call, all before the agent touches the actual system behind the tool.
It also handles the login problem properly. The agent gets a short-lived, scoped pass from the gateway rather than carrying a permanent password of its own. The real secrets stay at the gateway, not in the agent.
The limits, stated plainly: this works for tools, but not yet for the other things the MCP standard can carry. Only standard web APIs can be turned into tools this way. And the rules you set apply to the whole tool server at once, not to individual tools within it, so you cannot yet give one tool a tighter limit than its neighbor. Useful today, still maturing.
When agents start talking to each other
In November 2025, Microsoft added the last piece: governing agents that talk to other agents. Now all three kinds of traffic, an agent talking to a model, an agent using a tool, and an agent handing work to another agent, run through the same set of rules.
Picture a research agent that gathers findings and passes them to a second agent that writes the summary. Normally that hand-off happens directly, agent to agent, with nobody watching. With this in place, the hand-off routes through the gateway instead. The two agents still work exactly as before, and neither one changes its code. But now every hand-off is logged, counted against the spending limits, and screened for safety. If something goes wrong in a chain of five agents, you can see which hand-off caused it.
That last point is the real value. As soon as you have agents calling agents calling agents, the hard question during an incident is "which step went wrong?" Routing every hand-off through one place is what makes that question answerable.
This is the newest piece and the least finished. It works for one common style of agent-to-agent communication, with some rough edges, and Microsoft was still calling it preview as of mid-2026.
The identity problem nobody planned for
Gartner estimated in August 2025 that 40% of enterprise applications would include task-specific AI agents by the end of 2026, up from less than 5% in 2025. That is an eight-fold jump in a single year.
Here is the problem that creates. Every one of those agents needs an identity, a way to prove who it is and what it is allowed to do, just like an employee needs a login. But these non-human identities, the logins used by software rather than people, already outnumber human accounts in most companies by more than a hundred to one. A 2026 Cloud Security Alliance survey found only 15% of organizations feel confident they could stop an attack that rides in on one of these identities, and more than one in six do not even track when new AI identities are created.
88% of organizations confirmed or suspected an AI agent security incident in the prior year. 45.6% still rely on shared API keys for agent-to-agent authentication. Only 22% treat agents as independent identity-bearing entities.
— State of AI Agent Security 2026
The way this goes wrong with agents is specific. Agents pick up new permissions as they work. They launch helper agents that inherit their access. They string together actions across dozens of systems faster than any person could. And when an agent is simply handed a human's login, which is how most companies run them today, it inherits everything that person can reach, without any of the watchfulness a human session would get. The principle of giving each identity only what it needs quietly falls apart.
The gateway helps in two ways. First, it removes the API keys entirely. Instead of the agent carrying a password to reach the model, the gateway proves its own identity to Azure directly, and there is no key to be created, stored, leaked, or rotated. Second, when an agent needs to reach an outside tool, the gateway hands it a temporary, narrowly scoped pass rather than a permanent credential. The real secret never reaches the agent's code.
The shift in plain terms: agents get short-lived, limited passes handed out by the gateway instead of permanent keys they carry around. The security gain is real. The honest caveat is that you have not removed the secret, you have moved it. Whoever can edit the gateway's rules can make the gateway hand out a pass in its name. "No more API keys" is not "nothing left to protect." The thing to guard becomes who is allowed to change the gateway, and that deserves the same care the old keys did.
What is GA, what is preview, and why it matters
Before committing to APIM as your enterprise agentic governance layer, a clear-eyed reading of the maturity matrix is required. The token- governance and content-safety core is production-ready. The agent-orchestration and multi-provider layers on top are not yet, and the difference matters when you are scoping a production rollout.
| Capability | Status | What to know |
|---|---|---|
| Token limits (spending caps) | Ready now (since May 2024) | Not on the pay-per-call tier |
| Content safety screening | Ready now (since Sept 2024) | Limited on streaming responses |
| Semantic caching | Ready now | Needs a separate cache running alongside |
| Cost tracking and tagging | Ready now (all tiers) | "Thinking" cost breakdown still in preview |
| Spreading load across models | Ready now | Not on the pay-per-call tier |
| Turning APIs into agent tools | Ready now | Tools only; whole-server rules, not per-tool |
| Governing agent-to-agent traffic | Nearly there | One communication style; still preview as of mid-2026 |
| One doorway for every model | Preview | Older tiers must opt in |
| Single control room in Foundry | Preview | New tools only; coarse logging |
| Governing Claude through the gateway | Newer tiers only | Not available on older tiers |
| "Thinking" cost breakdown | Preview |

The cost and safety core is production-ready. The orchestration and multi-provider layers are still arriving.
The preview features worth watching now
One doorway for every model. This is the most interesting thing coming, and the one worth explaining with an example.
Today, talking to OpenAI's models and talking to Anthropic's Claude are two different conversations. Each one expects its requests in a different shape and sends its answers back in a different shape. So if your company uses both, your developers write the connection twice, and your governance rules get set up twice, once for each.
This feature collapses that into a single doorway. Your agents talk to one address, in one format. Behind the door, the gateway translates the request to whichever model you point it at, and translates the answer back. Switching an agent from a GPT model to Claude becomes a setting change, not a rewrite. And because everything comes through the one door, your spending limits and safety checks are written once and cover every model automatically.
Think of it like a universal power adapter. Your devices plug into one socket; the adapter quietly handles the differences behind the wall.
The reality check: right now it translates cleanly between OpenAI and Anthropic. Google's and Amazon's models can pass through but do not get the full translation yet. And it is still preview, so treat it as a direction, not a finished product. But the direction is the point. Add a new model vendor next year and you should not have to rebuild your controls. The doorway stays put; you just point it somewhere new.
A single control room. Announced in late 2025 and still in preview, this ties the gateway into Foundry, Microsoft's home base for building agents. Turn it on, and new tools you create there automatically run through the gateway instead of going straight to their destination. More useful still, it gives you one screen listing three things: every model, every agent, and every tool your organization runs, including agents running outside Azure entirely. For a leader trying to answer "how many AI agents do we actually have, and what can they touch?", that single inventory is the whole point.
The gaps are real. Only brand-new tools get routed automatically; existing ones are not pulled in for you. It covers one kind of tool, not all of them. And while it logs the overall traffic, it does not yet capture the fine detail of each individual tool call, so a deep investigation still means digging into that tool's own logs. The direction is clear, though: Microsoft wants one place where you can see and govern every agent you run, with the gateway doing the enforcing underneath.
Seeing the cost of "thinking" models. The cost-tracking control is finished, but one valuable piece is still in preview: separating out the cost of a model's reasoning. The newest models "think" before they answer, and that thinking burns tokens, often more than the question and the answer combined. If you cannot see that thinking cost on its own, you can see the total bill but not what is driving it. This preview setting breaks it out, so on reasoning-heavy work you can tell which agent or task is running up the cost. Running one of these models without it is like getting an electric bill with no breakdown: you know the number, not the cause.
A catch if you use Claude. Governing Anthropic's Claude through the gateway only works on the newer "v2" versions of APIM. The older versions do not support it. So a company that set up the gateway on an older version for its OpenAI models, and later wants to bring Claude under the same controls, has to move to the newer version first. That is a real piece of work, not a quick setting change. The lesson is simple: if Claude is anywhere on your roadmap, start on a v2 version now.
The reference architecture: one control plane for three surfaces
Microsoft's own guidance for this, its reference design for running AI agents at scale, draws a hard line between two layers: the layer that sets and enforces the rules, and the layer where the agents actually do their work.
The gateway lives in the rules layer. It handles the spending limits, the identity checks, the safety screening, and the record-keeping. It does not care whether the request underneath is an agent calling a model, an agent using a tool, or an agent handing work to another agent. The same rules, the same access controls, and the same logs cover all three.
The work layer is where the agents run, use their tools, and call their models. The one firm rule: every outbound call has to go through the gateway. Agents are never allowed to reach a model or a tool directly.
That separation is what makes the whole thing hold up over time. Add a new agent platform, a new model vendor, or a new kind of tool, and you change nothing in the rules layer. The gateway already sees all the traffic, so anything new is governed automatically the day it arrives, not patched in afterward.
The practical path for a team starting today:
- Put the gateway in front of your models, with a separate identifier for each team and application.
- Set both a per-minute speed limit and a monthly budget for each one.
- Turn on content-safety screening for every model the agents can reach.
- Tag every request with its team and agent so you can track who spent what.
- Switch the gateway over to password-free access to your models, and delete the old keys.
- Turn your existing APIs into agent tools through the gateway.
- Route agent-to-agent hand-offs through the gateway too, once that piece is fully released.
Steps 1 through 5 are available and production-ready today. Steps 6 and 7 are either available now or nearly there. You can start building this now.
The honest competitive position
Every major gateway vendor pivoted toward agents in late 2025. Kong has been the loudest, claiming the broadest coverage of all three traffic types. Amazon leans on its Bedrock service for model controls, with a separate gateway alongside. Several smaller players, Gravitee, Tyk, Truefoundry, entered the same race. The whole industry has landed on the same idea: the gateway is where you govern AI.
Microsoft's advantage is that the AI controls are built in and feed the same monitoring tools its enterprise customers already use, rather than being a bolt-on. Nothing extra to stitch together. And the Foundry control room, once it is finished, aims to be the single place you see and govern every agent you run, wherever it runs.
The weaknesses are equally real. Governing Claude requires the newer version of the product, a hard stop for anyone standardizing on it. Company-wide budgets need the per-region math described earlier. The cheapest pay-per-call tier is left out of the spending controls entirely. And the tool feature, useful as it is, covers only part of what the agent-tool standard can do.
The bottom line: for a company already committed to Azure, this is the obvious default. The claim that it is the single most complete option, though, is genuinely contested. Know the limits before you bet your governance on it.
What comes next
The shift in 2026 is not that AI governance suddenly matters. It is that the tools to actually enforce it now exist and are largely ready to use. The gaps that turned the 2025 failures into headlines, agents reaching systems with nothing watching, no record of who spent what, no control at the point where the agent acts, are closeable today with what this gateway already ships.
By 2027, over 40% of agentic AI projects will be canceled and 40% of enterprises will demote or decommission autonomous agents due to governance gaps identified only after production incidents.
— Gartner, June 2025
That is not a prediction about technology. It is a prediction about governance timing. The organizations that build the API gateway layer before the incident will not be in that 40%. The organizations that wait for the incident to explain the budget request will.
The trust boundary moved. The question is whether your governance architecture moved with it.
Matthew Kruczek is Managing Director at EY, leading Microsoft domain initiatives within Digital Engineering. Connect with Matthew on LinkedIn to discuss agentic governance architecture and API gateway enforcement patterns for production agents in your organization.