You wrote the rule down. You put it in capital letters, added "ALWAYS" and "CRITICAL," and three thousand tokens later the agent ignored it anyway. That is not a prompting failure. It is a category error, and neurosymbolic AI explains why.
If you only have a minute, here's what you need to know.
- Agents forget your rules because natural-language instructions are soft. The model weighs them probabilistically against everything else in context, so they get diluted as the conversation grows. This is measured, not anecdotal.
- Writing better rules does not fix this. You cannot solve a probabilistic-enforcement problem with better-worded probabilistic instructions.
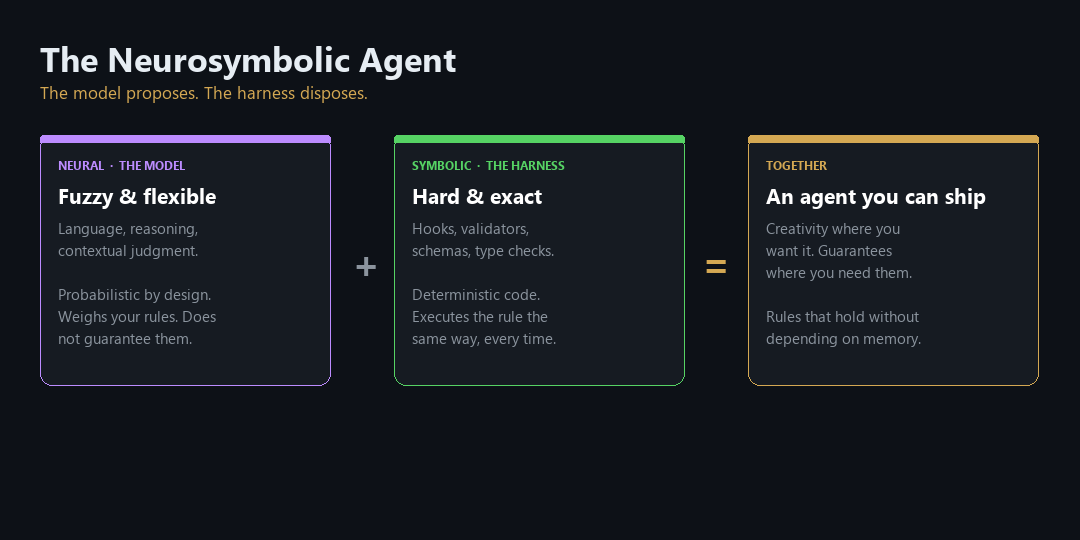
- Neurosymbolic AI is the pairing of neural systems (pattern recognition, language, fuzzy judgment) with symbolic systems (explicit rules that execute the same way every time). The symbolic half does not "remember" a rule. It enforces it.
- The harness around your agent is the symbolic half. Hooks, validators, type checkers, schemas, and deterministic tool execution are what turn a hopeful sentence into a guaranteed constraint.
- The markdown file does not go away. Its job changes: it communicates intent to the model, while the harness guarantees the outcome. Write the rule once for the neural side, enforce it once on the symbolic side.
The wall I keep hitting
The other night I was deep in a Claude Code session, the kind where you have been pairing with the agent for a couple of hours and real work is actually getting done. Early on I had given it the rules. Use immutable types. Follow our naming conventions. The usual contents of the CLAUDE.md file every team now keeps.
Somewhere around hour two, it quietly broke one of them. Not maliciously, not because the rule was unclear. It just stopped honoring it. I had written that rule in plain English, in capital letters, and the agent sailed right past it as if it had never been there.
I have hit this wall enough times to know that rewriting the rule harder does not fix it. So instead of reaching for better wording, I started thinking about enforcement. How do you write a rule that cannot be ignored, rather than one you hope gets followed? That question turns out to have a name, and it goes back forty years in AI research. It is called neurosymbolic AI, and it explains both why my rule got forgotten and what to actually do about it.
The rule you wrote is a suggestion
Start with why it happened. Language models do not treat your context evenly. Performance is highest when the information they need sits at the very beginning or the very end, and it degrades, sometimes sharply, when that information is buried in the middle. Researchers named this the "lost in the middle" effect. The model did not get dumber between hour one and hour two of my session. My rule had drifted into the part of the context the model pays the least attention to.
It gets worse the more you load in. Chroma tested 18 frontier models, including Claude 4, GPT-4.1, and Gemini 2.5, and found that every one of them degraded as input length grew. A model advertising a 200,000-token window showed significant degradation at 50,000 tokens. The number on the box is not the number at which the model stays sharp.
Every one of 18 frontier models degraded as input grew. A model with a 200,000-token window showed significant degradation at 50,000.
— Chroma, "Context Rot," 2025
Stack more rules into that shrinking effective window and the problem compounds. The model starts making contradictory choices and quietly dropping the instructions that mattered most to you.
This is the part most teams get wrong: they treat forgotten rules as a writing problem. So they rewrite the rule. They bold it. They add three exclamation points and the word "MUST." None of it works for long, because none of it changes the underlying mechanic.
A rule in a CLAUDE.md file, an agent system prompt, or an
AGENTS.md is not a constraint.
It is a suggestion weighted by probability. The model
reads it, assigns it some influence, and then balances it against the
other ten thousand tokens competing for the same attention. Most of the
time the suggestion wins. Sometimes it does not. And "sometimes it does
not" is precisely the failure mode that makes enterprises refuse to put
agents anywhere near production.
Two halves of AI history, finally in the same system
To understand the fix, it helps to remember that AI has two lineages.
The first is symbolic AI: rules, logic, knowledge bases, and programs that execute discrete steps. It dominated the field for decades. It is precise, verifiable, and utterly reliable. It is also brittle. A symbolic system does exactly what you told it and nothing more, which is wonderful until reality presents a case you did not anticipate.
The second is neural AI: the large language models running your agents today. They are flexible, handle ambiguity, and generalize across tasks no one explicitly programmed. They are also probabilistic by construction. They do not guarantee anything. They predict.
Neurosymbolic AI is the deliberate combination of the two. A neural component handles perception, language, and fuzzy judgment. A symbolic component handles the rules that must hold every single time. This is not a fringe academic idea. Adoption accelerated through 2025 specifically as a response to LLM hallucination and unreliability. Amazon's Vulcan warehouse robots pair neural AI for vision and tactile sensing with symbolic AI that enforces the safety constraints and placement logic the neural layer cannot be trusted to guarantee on its own. The same company runs a decade-old Automated Reasoning group whose formal-verification methods now sit underneath those systems.

The neural layer proposes. The symbolic layer disposes. The harness is the symbolic half.
2025 was the year neurosymbolic AI moved from research to deployment, driven by the need to constrain LLM hallucination.
— Amazon Science; "Defining Neurosymbolic AI," arXiv 2507.11127
The insight that matters for your agents is simple and slightly uncomfortable. The symbolic half does not remember rules. It executes them. A type checker does not "try to recall" that you wanted immutable types. It fails the build if you violate the rule, the same way, every time, regardless of how long the conversation has run or where the instruction sat in context. There is no attention budget. There is no middle of the window to get lost in.
The harness is the symbolic layer
Now connect that to how agents actually run.
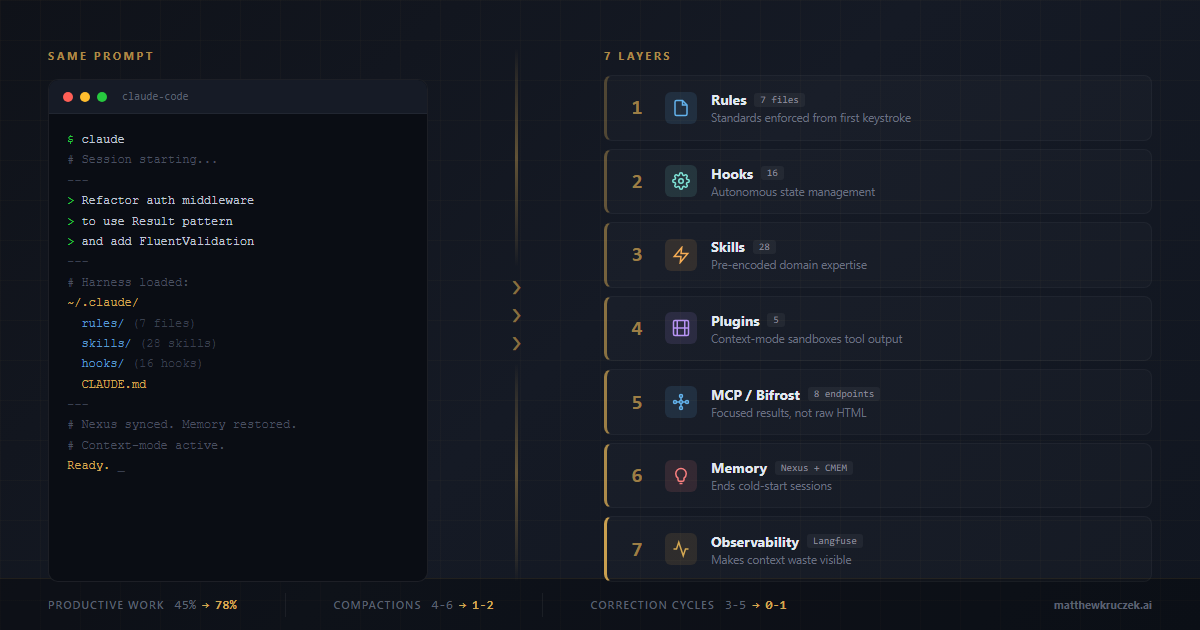
An agent is never just a model. It runs inside a harness: the layer that decides which tools the model can call, validates inputs and outputs, runs hooks before and after actions, checks schemas, and executes deterministic code. Most teams think of the harness as plumbing. It is not plumbing. It is the symbolic half of a neurosymbolic system, and you have probably been underusing it.
This reframes the markdown file you have been fighting with, and it is worth being clear about what those files are good at, because they are good at a great deal. A well-written CLAUDE.md is the best mechanism we have for communicating intent to a model. It shapes the agent's judgment, carries your conventions, and encodes the "how we do things here" that a generic model could never guess on its own. Keep writing them. The mistake is not writing them. The mistake is asking prose alone to provide a hard guarantee, because prose lives on the neural side of the system, and the neural side does not deal in guarantees. It deals in probabilities. The markdown does not need replacing. It needs a little help from the other half.
Your coding standard says "always use immutable types." Write that as a paragraph in CLAUDE.md and you will see it honored most of the time and silently violated in the long sessions where it matters most. Pair the same rule with a check in the harness, and it is enforced on every action, forever, with zero dependence on whether the model remembered it. Same rule. One version is a hope. The other is a guarantee.
So what does "enforce it in the harness" actually mean in practice? It means code. In Claude Code the mechanism is a hook: a shell command the harness runs automatically at a defined point in the agent's lifecycle, before a tool call, after a file edit, or before the agent is allowed to finish. The hook is a script you write. It inspects the action the model is about to take and returns a decision. If your immutable-types check fails, the hook exits non-zero and the edit is blocked before it ever lands on disk. The model does not get a vote. Other harnesses expose the same idea under different names: pre-action validators, output schemas enforced through constrained decoding, tool allow-lists, policy engines. The common thread is that a rule is executed by deterministic code sitting outside the model, not interpreted by the model inside its context. That is the entire mechanical difference between a rule that holds and a rule that hopes.
The pattern generalizes:
- A naming convention in prose becomes a validation hook that rejects non-conforming names.
- "Never touch the payments module without approval" in prose becomes a tool permission the model cannot route around.
- "Output must match this format" in prose becomes a schema the harness enforces through constrained generation.
- "Three levels of approval for infrastructure changes" in prose becomes a state machine the agent must pass through.
In each case the markdown still exists. It tells the model what you intend so its neural judgment points the right direction. But the harness is what makes the rule true.
I have written before about the harness as the thing that actually separates good agent output from bad, in The Harness Engineering Playbook and in why the harness is the multiplier. Those pieces are the "how I build it" side: the specific hooks, the enforcement levels, the scaffolding. This one is the "why it works" side. Neurosymbolic AI is the theory underneath the practice, and once you see the harness as the symbolic half, the hooks stop looking like configuration and start looking like the half of the system that guarantees anything at all.
Two kinds of neurosymbolic, and which one you are building
The term carries two meanings, and it is worth knowing which one applies to your agents. The academic version means integrating symbolic reasoning directly inside the model architecture, with systems like Logic Tensor Networks or DeepProbLog. That is deep research territory, and it is not what most agent teams are building.
The version that matters for production is system-level neurosymbolic: a neural model wrapped in a symbolic scaffold. The model reasons, drafts, and recommends. A deterministic layer around it decides what is actually allowed to happen. Both meanings are legitimate and both appear in the literature, but the second is the one you can put to work this quarter, and it is exactly what the most serious applied work is doing. Recent research compiles regulatory policies into Lean 4 proofs and treats every proposed agent action as a conjecture the kernel must prove before it executes. Other work translates safety properties into first-order logic and uses an SMT solver to block any non-compliant action at runtime. Different tools, same architecture: a neural model composed with a symbolic layer that gets the final say.
Treat model output as untrusted by default. Every action must prove it satisfies the system's constraints before it executes, or it is corrected, rejected, or routed to a fallback.
— "From Harness to Enforcement," 2026
That is the whole idea in one sentence. The model proposes. The symbolic layer disposes.
What this looks like in a regulated enterprise
Imagine a global bank deploying an agent to help draft and route trade approvals. The compliance rule is non-negotiable: trades above a threshold require a second human approver, and certain counterparties are off-limits entirely.
The naive build puts those rules in the agent's system prompt and hopes. It will work in the demo. It will work for the first hundred trades. Then a long, messy session will push the rule into the forgotten middle of the context, the agent will confidently approve something it should have escalated, and the bank will spend the next six months explaining that to a regulator.
The neurosymbolic build never lets the model make that call. The threshold check and the counterparty blocklist live in the harness as deterministic gates. The agent can read, reason, draft, and recommend all day, but it physically cannot emit an approval that violates the policy, because the symbolic layer rejects the action before it executes. The bank is no longer trusting the model to remember the rule. It has made the rule impossible to break. That is the difference between an agent you pilot and an agent you put in production.
How to apply this Monday morning
You do not need a research lab. You need to stop asking prose to do the symbolic layer's job. Use this test on every rule you currently keep in a markdown file.
The two-layer test. For each rule, ask one question: what happens if the model ignores this? If the honest answer is "a real problem," the rule does not belong only in prose. It needs a symbolic enforcement counterpart in the harness. If the answer is "a minor stylistic miss," prose is fine. Spend your engineering effort enforcing the rules whose violation actually costs you something.
This week. Audit your CLAUDE.md, agent prompts, and rule files. For every rule, label it "preference" or "guarantee." Anything labeled guarantee that has no enforcement mechanism is a latent incident.
This month. Move your top three guarantees out of prose and into the harness. Start with the cheapest deterministic checks you already own: linters, type checkers, formatters, schema validation, and pre-action hooks. Keep the prose, but let it point at the enforcement rather than pretend to be it.
This quarter. Build the enforcement layer into your agent platform as a first-class concern, not an afterthought. Define which rules are hard constraints, encode them where the model cannot bypass them, and treat every agent action as something that must pass validation before it runs. For the highest-stakes domains, look at formal methods. Compiling policy into a checker a model cannot argue with is no longer exotic.
The model will keep forgetting. The harness never will.
The industry spent two years trying to make agents reliable by making the model better. Bigger context windows, sharper reasoning, more careful prompts. Those help. They do not make a probabilistic system deterministic, and they never will, because that is not what neural systems are for.
Reliability does not come from the model remembering your rules. It comes from building a system where the rules do not depend on memory at all. That system has a name. It is neurosymbolic, and the symbolic half is the harness you already have and have not been using hard enough.
Keep writing the rules. Just stop expecting them to enforce themselves.
Matthew Kruczek is Managing Director at EY, leading Microsoft domain initiatives within Digital Engineering. Connect with Matthew on LinkedIn to discuss neurosymbolic enforcement patterns for production agents in your organization.
References
- Liu, N. F., et al. "Lost in the Middle: How Language Models Use Long Contexts." Transactions of the ACL, 2024. arxiv.org
- Chroma. "Context Rot: How Increasing Input Tokens Impacts LLM Performance." Technical Report, July 2025. research.trychroma.com
- "Neuro-symbolic AI." Wikipedia. en.wikipedia.org
- Amazon Science. "The technology behind Amazon's GenAI-powered shopping assistant, Rufus." 2025. amazon.science
- "Defining Neurosymbolic AI." arXiv 2507.11127. arxiv.org
- "From Harness to Enforcement: Designing Deterministic Guardrails for LLM Systems." Medium, 2026. bh3r1th.medium.com
- "AI Agent Guardrails: Rules That LLMs Cannot Bypass." AWS / DEV Community. dev.to
- "Type-Checked Compliance: Deterministic Guardrails for Agentic Financial Systems Using Lean 4 Theorem Proving." arXiv 2604.01483. arxiv.org
- Anthropic. "Equipping agents for the real world with Agent Skills." October 2025. anthropic.com