If you only have a minute, here's what you need to know.
- The AI operating model is not one of the eight dimensions on the scorecard. It is the structural decision that determines how well you execute across all of them. Organizations spend months selecting platforms, building data pipelines, and recruiting talent without ever deciding how AI capability will be organized, governed, and deployed across the business.
- Three operating models dominate enterprise AI: centralized (a single AI team owns everything), hub-and-spoke (a central team provides platform and standards while business units build within guardrails), and federated (each business unit runs its own AI program with lightweight coordination). Each model works, but only at the right maturity level.
- The most common failure is not choosing the wrong model. It is not choosing at all. Most organizations inherit whatever structure their first AI team created, and by the time the limitations become visible, the organizational patterns are entrenched.
- For most enterprises, hub-and-spoke is the target state. Centralized gets you started. Federated is where mature organizations eventually arrive. But most enterprises with 5 to 20 production AI use cases should be running hub-and-spoke, and most of them are not.
- This article gives you the diagnostic for identifying which model you are actually running today, the criteria for when to transition between models, and the specific failure modes that trap organizations in structures that cannot scale.
In the previous article, I laid out the six-month workstream for getting your data AI-ready. If you have been following the series in order, you might expect this article to cover the next scorecard dimension: Technology Infrastructure. I am skipping it deliberately. As I argued in the scorecard piece, technology accounts for roughly ten percent of what determines AI success, and most enterprises are already at or near 3.0 there. The bottleneck is almost never the platform. It is the organization wrapped around the platform.
That organizational structure is the AI operating model, and it is the subject of this article. The operating model is not one of the eight dimensions on the scorecard. It is the structural decision underneath them. Your scorecard measures Talent and Skills, Process Maturity, Governance, and the other dimensions individually, but the operating model determines how those dimensions interact at scale: how resources are allocated, how governance is enforced, how knowledge flows between teams, and how decisions get made about which AI initiatives move forward. Get this wrong and every dimension on the scorecard hits a ceiling. Get it right and the dimensions reinforce each other.
Data readiness determines whether AI can work. The operating model determines whether it can scale. Even organizations with clean data, strong executive sponsorship, and a well-prioritized roadmap will hit a ceiling if the organizational structure around AI cannot support the volume and complexity of concurrent initiatives. An organization trying to run 15 AI use cases through a five-person center of excellence is not going to scale, no matter how good the data or how committed the executive sponsor.
The operating model nobody chose
Here is the pattern I see most often. An organization starts its AI journey by forming a small team, usually three to eight people, under the CTO, CDO, or a senior VP who volunteered. That team runs the first two or three pilots. Some succeed. Leadership gets excited. More use cases are approved. More business units want in.
The original team, which was designed to explore, is now expected to deliver at scale. Nobody makes a deliberate decision about how to restructure. The team grows incrementally. Business units start asking for dedicated resources. Some BUs hire their own data scientists without telling the central team. Others build shadow AI capabilities using SaaS tools that nobody in IT knows about.
Eighteen months later, the organization has AI work happening in five different places with three different tech stacks, no shared governance, and no mechanism for sharing what works. When someone finally proposes "we need an AI operating model," the conversation is about ratifying a mess, not designing a system.
The operating model was never designed. It was inherited. That is the structural failure this article diagnoses.
Three models, one decision
Every enterprise AI operating model is a variation of one of three patterns. Understanding the trade-offs of each is the prerequisite for making a deliberate choice.

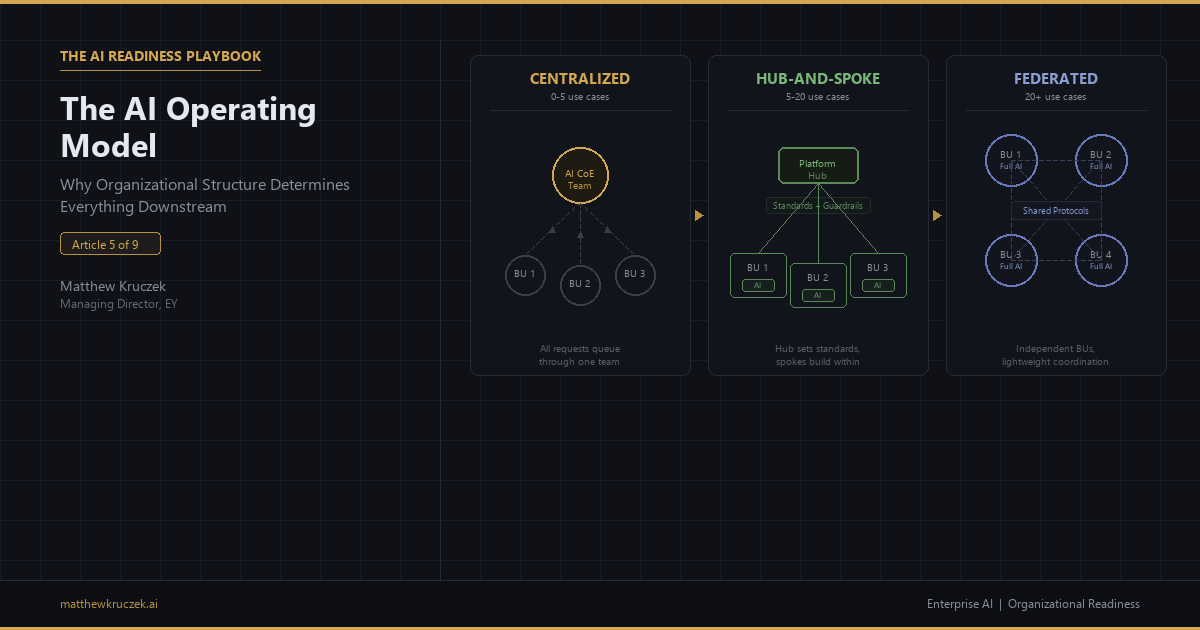
Figure 1: The three enterprise AI operating models. Centralized routes all work through a single team. Hub-and-spoke sets standards centrally while business units build within guardrails. Federated gives each BU full independence with lightweight coordination.
Centralized (Center of Excellence)
In a centralized model, one team owns AI strategy, development, deployment, and operations. All use cases route through a single intake queue. Standards are uniform because there is one team setting them.
A 2.0 on centralized looks like this: a small CoE of five to ten people attempting to serve 20 or more use cases across multiple business units. They are the bottleneck, and everyone knows it. Business units wait four to six months for their use case to reach the front of the queue. When it does, the AI team lacks the domain context to build something useful without weeks of knowledge transfer. The best domain experts and business analysts are never in the room because they sit in the business units, not on the AI team.
A 4.0 on centralized looks like this: a well-resourced team of 15 to 25 people with clear prioritization authority, direct executive sponsorship, and embedded business liaisons from each major BU. The team controls the intake process and can say no to low-priority requests without political consequence. Standards, evaluation frameworks, and deployment pipelines are mature and documented.
Centralized works when you are early in AI maturity, running fewer than five production use cases, in a heavily regulated industry where consistency is non-negotiable, or in an organization under 5,000 employees where a single team can maintain direct relationships with every stakeholder.
Centralized breaks when you exceed eight to ten concurrent use cases. The bottleneck becomes existential. Business units that cannot get AI resources through the official channel start building their own, and you lose governance without gaining speed.
Hub-and-Spoke
In a hub-and-spoke model, a central team (the hub) provides the platform, standards, governance framework, and shared capabilities. Business unit teams (the spokes) have embedded AI engineers and data scientists who build and deploy within the guardrails the hub defines.
The hub does not build every use case. It builds the infrastructure that lets spokes build use cases safely and efficiently. Think of it as the difference between building houses and building the building code. The hub writes the code. The spokes build the houses.
A 2.0 on hub-and-spoke looks like this: the organization renamed its CoE as a "hub" but nothing changed. Spokes have no real autonomy. Every use case still routes through the center. Or the opposite failure: spokes have autonomy but no guardrails, producing inconsistent, ungoverned AI that nobody can audit or maintain. The "hub" is a standards team that nobody listens to.
A 4.0 on hub-and-spoke looks like this: the hub owns platform infrastructure, MLOps, evaluation frameworks, model governance, and a shared data layer. Spokes own use case identification, development within defined guardrails, and business-side change management. There is a clear interface between hub and spoke responsibilities. Spokes can ship a new use case to production without hub approval if it stays within pre-certified patterns. Novel patterns (new model types, new data sources, new risk categories) require hub review through a standing sprint that operates on a two-week cadence.
Hub-and-spoke works when you have five to twenty production use cases, multiple business units with different AI needs, and enough AI talent to staff both a hub and at least two spokes. It is the target state for most large enterprises.
Hub-and-spoke breaks when the hub becomes a bureaucracy that slows spokes down without adding governance value, or when spokes are not genuinely staffed with competent AI engineers and end up dependent on the hub for everything anyway.
Federated
In a federated model, each business unit runs its own AI program with its own talent, budget, and roadmap. Shared protocols and interoperability standards exist but are lightweight. There is no central AI team. There may be a small coordination function that maintains shared standards and facilitates cross-BU learning, but it does not have delivery responsibility.
A 2.0 on federated looks like this: there is no coordination at all. Every BU is doing AI independently with different vendors, different platforms, and different standards. Massive duplication of effort. No shared learnings. A customer-facing AI in one BU contradicts the output of a customer-facing AI in another. Governance is an afterthought.
A 4.0 on federated looks like this: federated by design, not by accident. Shared data contracts, evaluation standards, and an interoperability layer mean that AI capabilities built in one BU can be consumed by another. Each BU has a mature AI team with full-stack capability. A lightweight central function coordinates standards and hosts a regular forum for sharing what works.
Federated works when every BU has deep AI talent, a mature engineering culture, and the discipline to follow shared standards without central enforcement. In practice, this means tech-native companies and organizations with 50 or more production AI use cases across multiple BUs.
Federated breaks everywhere else. Most enterprises do not have enough AI talent to staff every BU independently. Most do not have the engineering maturity to maintain governance without a central enforcement function. Declaring a federated model before BUs have the capability to operate independently is how you get ungoverned AI at scale.
The maturity progression
The three models are not options on a menu. They are stages on a maturity curve. Most organizations should follow a deliberate progression:

Figure 2: The maturity progression from centralized to federated. Hub-and-spoke is the target state for most enterprises. Federated is an earned state, not a declared one.
Stage 1 (0 to 5 production use cases): Centralized. A single team builds institutional knowledge, establishes standards, and proves the value of AI. The team should be building the governance frameworks and platform capabilities that will later enable spokes.
Stage 2 (5 to 20 production use cases): Hub-and-Spoke. The central team transitions from building everything to enabling business units. The first two spokes should be BUs with the strongest domain expertise and the highest volume of AI demand. Expand spokes gradually, not all at once.
Stage 3 (20+ production use cases, mature BUs): Federated. Only after every BU has demonstrated the capability to build, deploy, and govern AI independently. The hub transitions to a lightweight coordination function. This is an earned state, not a declared one.
The most common mistake is not the choice of model. It is the timing of transitions. Organizations that stay centralized past five to eight use cases create bottlenecks that erode trust in AI. Organizations that jump to federated before BUs are ready create ungoverned AI that erodes trust in governance.
Common failure modes
The accidental model. Nobody made a choice. The structure evolved organically from the first team that started doing AI. By the time leadership recognizes the problem, the political and organizational cost of restructuring is significant. The solution is to make the choice deliberately and early, ideally during the strategic alignment work from Article 3.
The bottleneck CoE. A centralized team that refuses to transition to hub-and-spoke because the team lead views decentralization as a loss of control. Business units respond by building shadow AI. The organization ends up with the worst of both worlds: a central team that controls nothing and BUs that govern nothing.
The hub that isn't. An organization declares hub-and-spoke but the hub still builds everything. Spokes exist on an org chart but have no real AI talent and no autonomy. Every decision still routes through the center. The label changed. The structure did not.
Premature federation. Leadership declares that "every BU should own its own AI" before any BU has the capability to do so. The result is 15 BUs each reinventing basic MLOps, each hiring one data scientist who burns out in six months, and no shared governance. This looks like innovation from a distance. Up close it is chaos.
Scoring 2.0 versus 4.0
A 2.0 organization has no deliberate operating model. AI work is happening in multiple places without coordination. There is no shared platform, no governance framework, and no mechanism for deciding which BU gets AI resources when demand exceeds supply. The executive team cannot articulate how AI is organized across the company, who is accountable for what, or how decisions about AI investment are made at the BU level.
A 4.0 organization has a deliberately chosen operating model that matches its maturity level. The model has clear accountability: who builds, who governs, who prioritizes. A shared platform reduces duplication. Governance operates at the speed of the model (standing sprints, not ad hoc reviews). Knowledge flows between teams through documented patterns and regular cross-team forums. The executive team can explain the structure and the rationale behind it.
The gap between 2.0 and 4.0 is not a technology gap. It is a decision that leadership has not yet made.
What to do this week
Name your current operating model. Pull your AI leadership together and answer honestly: are we centralized, hub-and-spoke, or federated? If nobody can answer that question quickly, you are running the accidental model, and that is its own diagnosis.
Count your concurrent use cases. If you have more than eight active AI initiatives running through a centralized team, you are overdue for hub-and-spoke. The bottleneck is already visible to the business units waiting in queue, even if it is not visible to the central team.
Assess spoke readiness. If you are considering hub-and-spoke, identify the two BUs best positioned to become spokes. Do they have AI-literate leadership? Domain experts willing to work alongside AI engineers? Budget for dedicated headcount? A spoke without these prerequisites is a spoke that will fail and blame the model.
Define the hub's interface. The single most important design decision in hub-and-spoke is what the hub owns versus what the spokes own. Draft a one-page "interface contract" that specifies: the hub provides X (platform, governance, evaluation), the spoke provides Y (use case selection, domain data, change management), and handoffs happen via Z (defined ceremonies, shared tools, escalation paths).
The scorecard in Article 1 measures eight dimensions individually, but the operating model is what determines how those dimensions work together at scale. Article 2 gave you the executive sponsor who owns the transformation. Article 3 gave you the prioritization framework that determines what the model needs to support. Article 4 gave you the data workstream that runs within the model. This article gives you the structural decision. The next article in the series turns to Talent and Skills: how to build the AI literacy and practitioner depth that makes your chosen operating model work.
Matthew Kruczek is Managing Director at EY, leading Microsoft domain initiatives within Digital Engineering. Connect with Matthew on LinkedIn to discuss AI operating models and organizational readiness for your enterprise.
References
- McKinsey. "Rewired: The McKinsey Guide to Outcompeting in the Age of Digital and AI." Hub-and-spoke as the dominant model among AI leaders. mckinsey.com
- Kruczek, M. "The AI Readiness Scorecard." The eight-dimension framework for diagnosing AI readiness. matthewkruczek.ai
- Harvard Business Review. "Building the AI-Powered Organization." The structural prerequisites for scaling AI beyond experimentation. hbr.org
- Deloitte. "State of AI in the Enterprise, 6th Edition." Organizational structure as the leading barrier to scaling AI past pilot. deloitte.com
- Kruczek, M. "Your Data Is Not AI-Ready." Data readiness as the workstream that runs within the operating model. matthewkruczek.ai
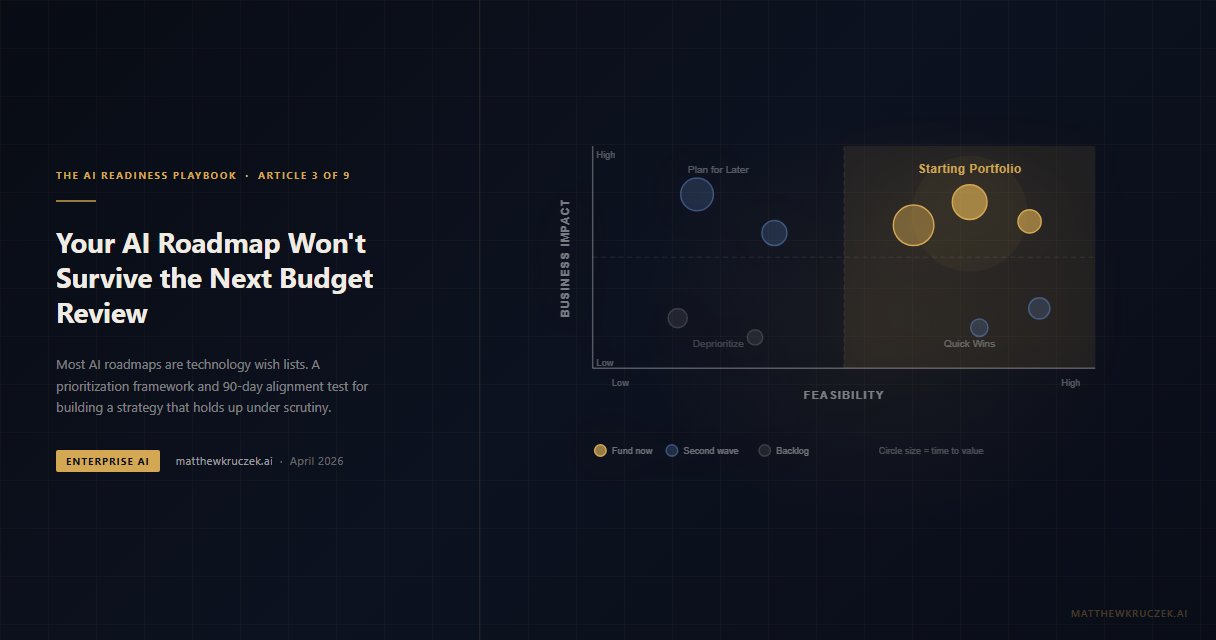
- Kruczek, M. "Your AI Roadmap Won't Survive the Next Budget Review." Strategic alignment as the prerequisite for operating model design. matthewkruczek.ai
This is Article 5 of 9 in "The AI Readiness Playbook" series, a step-by-step methodology for making your organization AI-ready.