Every vendor now sells a "self-learning" agent. Almost none of them have one. Here is the mechanism behind real self-improvement, and the five-second test that tells you whether the thing in front of you actually changes or just keeps better notes.
If you only have a minute, here's what you need to know.
- A deployed model does not change while it runs. Its weights are frozen, and it forgets everything between calls. "Self-learning" cannot mean the model is getting smarter mid-conversation, because mechanically it cannot.
- Self-improvement is something you build around the model, not a property of the model. There are five distinct places the improvement can live, from a notes file all the way down to the model's own weights. They are not the same thing, and most products sit on the bottom rung.
- Every rung runs the same engine: try something, check if it worked, keep what worked. The only thing that changes is what gets kept. Once you see that, the hype sorts itself.
- The five-second filter is the delete test. If wiping the agent's memory store would make it as dumb as day one, the model never learned anything. A database got bigger.
- Real self-improvement only works where a machine can grade the output. Code that passes tests can improve itself. A strategy memo cannot grade itself, so an agent writing memos can only accumulate, not learn. The grader is the whole game.
The washing has started
Gartner went on record in June 2025 with a number that should reframe how you read every agent pitch you will hear this year.
Only about 130 of the thousands of "agentic AI" vendors are real. Over 40% of agentic AI projects will be canceled by the end of 2027.
— Gartner, June 2025
They named the problem "agent washing": taking a chatbot, an assistant, or an old RPA script and relabeling it as an agent. The same thing is now happening one level up. Products that were "agents" last year are "self-learning agents" this year, usually with nothing underneath the new label except a vector database.
I want to give you the mechanism, in plain terms, so you can tell the difference in the room. No machine learning background required. By the end you will have a single question that cuts through most of it.
Start with two facts nobody says out loud
A large language model in production runs on two constraints that everything else follows from.
It is frozen. When the model is serving traffic, its internal settings, the "weights," do not change. Training happened months ago in a data center. The model you are talking to is a finished object. It is not adjusting itself based on your conversation any more than a printed book rewrites itself as you read it.
It has amnesia. Each time you call the model, it starts from nothing. It does not remember your last message, your last session, or anything it figured out yesterday, unless someone hands that information back to it as part of the new request.
So picture the thing you are actually deploying as a brilliant new hire with total amnesia. Razor sharp during the workday. Genuinely capable. And every single morning, they wake up remembering nothing about the job.
Hold that image, because now the question "how does it learn?" becomes a question everyone already knows the answer to. How do you make an amnesiac employee get better over time? Every technique sold as "self-learning" is just a different answer to that one question.
The five rungs of getting better
There are exactly five places the improvement can live. They form a ladder, from the flimsiest to the most permanent. Picture the same amnesiac employee climbing it.
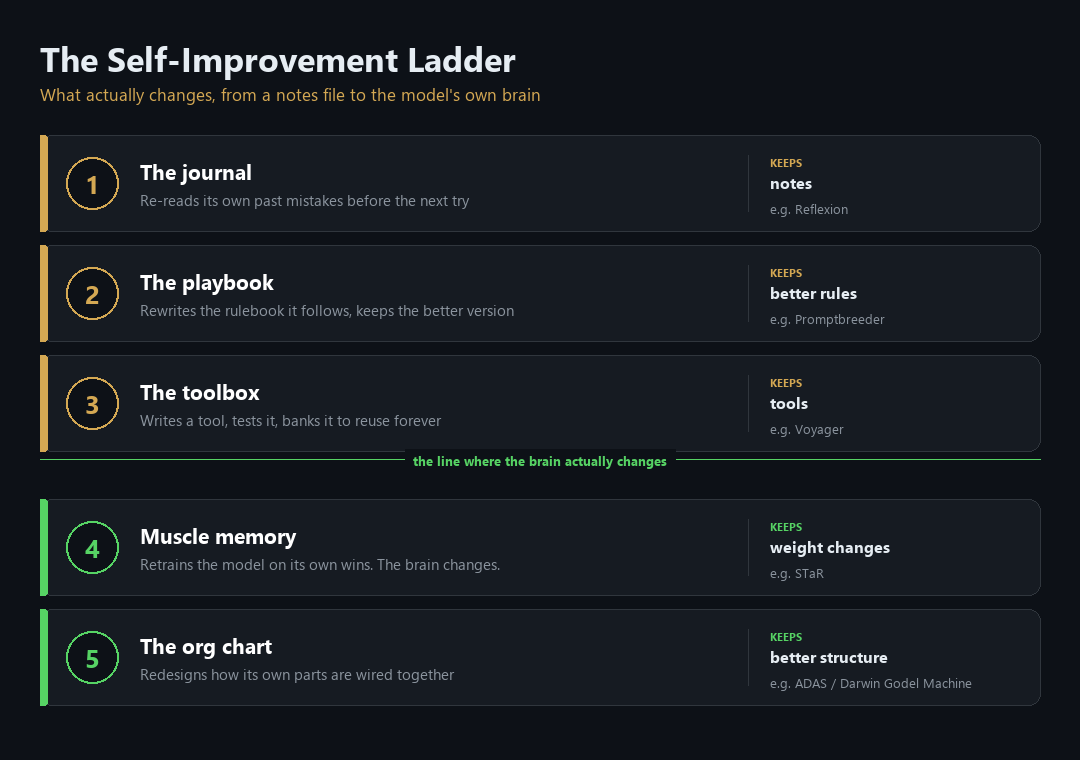
Five rungs of what actually changes, from a journal of notes to the model's own weights and structure.
Rung 1, the journal. After each task, the employee writes down what happened, especially the failures: "tried X, hit error Y, fixed it with Z." That note gets saved. Before the next task, the system digs up the relevant past notes and pastes them into the instructions. Nothing about the employee changed. The input got better, because it now arrives with yesterday's lessons stapled to the front. When a product says "it remembers and improves," this is almost always what it means. The research version is called Reflexion, where an agent reflects on its failures in words and feeds those reflections back into its next attempt.
Rung 2, the playbook. The employee has a standing set of rules they follow every time. Here the system points the loop at the rulebook itself. It tries a version of the rules, scores how the work came out, has the model propose an edited version, "rewrite these rules so you don't make that mistake again," tries the new version, and keeps whichever scores higher. Run that a few hundred times and the rulebook that survives is the one that works best. DeepMind's Promptbreeder does exactly this, and goes one level deeper: it also evolves the instructions for how to rewrite the rules. The difference from rung 1: a journal adds notes next to the rules. A playbook rewrites the rules themselves.
Rung 3, the toolbox. When the employee hits something they cannot do in one move, they write a small program to do it, run that program to confirm it actually works, and if it does, file it in a toolbox with a label. Next time a similar job shows up, they grab the tool instead of working the problem out from scratch. Solve it once, never solve it again. This is Voyager, the agent that played Minecraft by writing its own code for skills like "mine wood" or "fight a zombie," banking the ones that worked, and composing them into harder and harder tasks. It learned for the price of writing software, with the underlying model never fine-tuned once.
Voyager unlocked key milestones up to 15.3x faster than the previous best agent, and reused its skill library to solve brand-new tasks in worlds it had never seen, all without touching the model's weights.
— Voyager, arXiv 2305.16291
Rung 4, muscle memory. Gather every transcript where the employee got it right. Feed those wins back in as training examples and actually retrain the model on them, so the behavior that used to need notes or tools is now baked into the model itself. This is the only rung where the brain changes. The Self-Taught Reasoner (STaR) does this: the model generates its own reasoning, the wrong answers get thrown out, and the model is retrained on its own correct reasoning, then the loop repeats. It is also the only rung that survives the test in the next section, because the improvement is now inside the model file, not in a database sitting beside it.
Rung 5, the org chart. The top rung is not the employee getting better at their own job. It is the employee redesigning the whole team. Most real agents are not one model working alone. They are several models arranged into a workflow: one drafts, another checks the draft, a third looks things up, and something decides the order they run in. That arrangement is the org chart. At rung 5, the agent rewrites its own org chart. It tries a new structure, add a reviewer step, split one job into two, change who hands the work to whom, scores how the whole team performed, and keeps the arrangement that worked better. This is the frontier, and it is real in the lab. Automated Design of Agentic Systems, and its sharper cousin the Darwin Gödel Machine, are research systems where the agent edits the code that wires it together and keeps the versions that get measurably better at coding. Powerful, and nowhere near your production environment yet.
The one engine underneath all five
Read those five again and the pattern is hard to unsee. Every rung runs the same three-step loop: try something, check whether it worked, keep what worked. The only thing that changes as you climb is what gets kept.
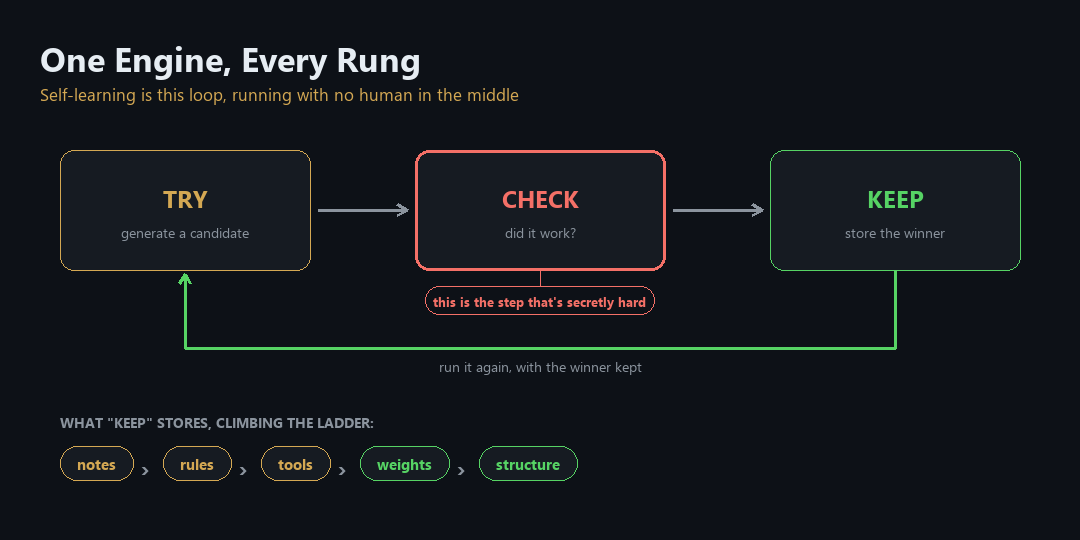
Try, check, keep, repeat. CHECK is the secretly hard step, and what KEEP stores changes by rung.
That is the whole thing. "Self-learning" is not magic and it is not one technology. It is this loop, pointed at a target, running without a human in the middle. Which means the interesting question is never "is it self-learning." It is "what is it keeping, and how does it decide what's worth keeping."
The five-second filter: the delete test
Here is the question to ask in the room.
"If I wiped its memory, would it be exactly as dumb as day one?"
The one question that sorts a notebook from a new brain.
If the answer is yes, you are looking at rung 1, maybe rung 2. The learning lives in a database you could erase, not in the agent. That is completely fine, a good notebook is valuable, but it is a notebook, not a new brain. Only rung 4 and above survive having their memory wiped, because the improvement moved into the model itself.
Two follow-ups make it airtight. Where does the improvement physically live? A text file, a vector database, the model's weights? If the vendor cannot point to the thing that changed, nothing is changing. And who actually did the learning? A large share of "self-improving" systems improved because humans watched the logs and tuned them. That is not self-anything. The "self" means the loop closes with no person in the middle.
Why coding agents are real and "self-improving" knowledge workers are not
There is one reason rungs 3 through 5 work in some places and collapse in others, and it sits in the middle step of the loop. Check whether it worked.
A person can only improve on their own if they can tell whether they did a good job. Same for an agent. An agent writing code can check itself: the tests pass or they fail, the program runs or it crashes. The grader is free, instant, and honest. That is why Voyager, STaR, and the coding systems genuinely climb. The world tells them the truth automatically.
Now ask an agent to write a market-entry strategy, or a customer email, or a board memo. What grades it? There is no test suite for a memo. Judging the output is as hard as writing it, and usually needs the very human you were trying to remove. With no automatic grader, the loop has no signal. The agent cannot keep "the good ones," because nothing reliable tells it which ones are good. It keeps everything, and "self-learning" quietly degrades into self-accumulating.
Self-improvement is easy where a machine can grade the answer and nearly impossible where it cannot. The grader, not the model, is the bottleneck.
This single distinction predicts which "self-learning agent" pitches are real. Verifiable domain with a cheap, honest grader, code, math, anything with a score, it can be real. Fuzzy domain where quality is a matter of judgment, it is a notes file with good marketing.
The governance problem you inherit
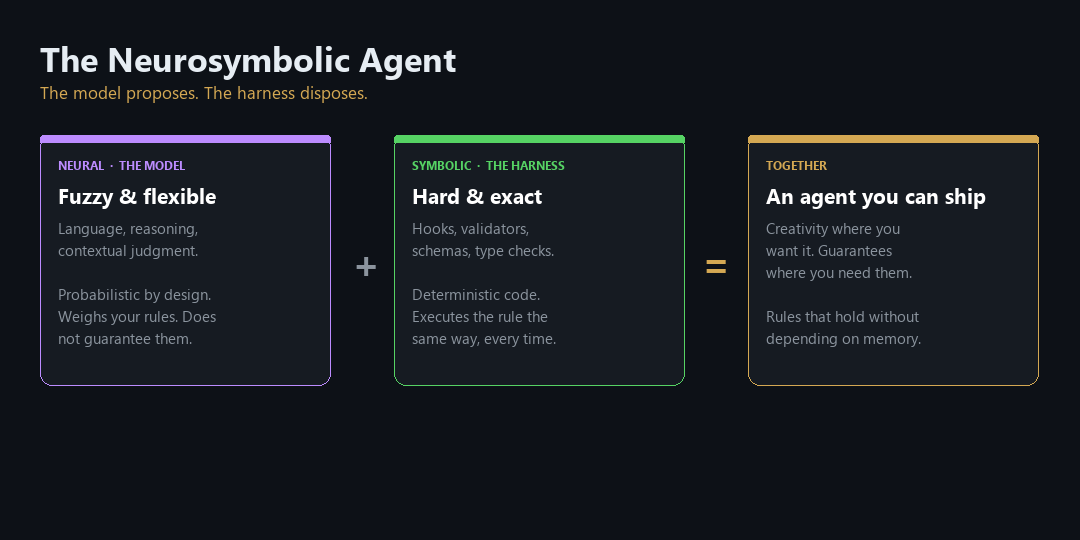
There is a catch for anyone responsible for risk, and it connects to a point I have made before about agents and the rules they are supposed to follow. A static security review assumes the thing you reviewed is the thing that runs. The moment an agent climbs past rung 2 and starts rewriting its own rules, tools, or wiring, your point-in-time approval is stale the instant the agent changes itself. The system you audited on Monday is not the system running on Friday.
This is the same reason I keep arguing that governance has to move from one-time review toward continuous evaluation at a control point every change has to pass through, the argument I make in the neurosymbolic case for the harness. A self-modifying agent is the clearest case for it. The more genuinely an agent learns, the less a one-time sign-off is worth, and the more you need a grader of your own sitting in the loop, checking not just "did it work" but "did it stay inside the lines."
What to do this week
You do not need a lab to apply this. You need to ask better questions and aim your money at the rung that matters.
Run the delete test on every "self-learning" claim you are evaluating. Ask the vendor where the improvement physically lives and what survives a memory wipe. Watch whether they can answer in concrete terms or retreat to adjectives.
Find your graders first. Before you fund a self-improving anything, ask what would automatically tell it whether it did well. If the honest answer is "a human reviews it," you are buying rung 1. Price it as a memory feature, not as learning.
Start at rung 1 on purpose, and call it what it is. A good memory layer over a frozen model is the highest-value, lowest-risk move available right now, and most enterprises have not done it well yet. Build it deliberately. Just do not let anyone in the building call it a brain.
Put a grader of your own in the loop before you allow anything above rung 2. If an agent is going to rewrite its own rules or tools in your environment, the control that checks each change is not optional. It is the feature.
The hype says your agent is learning. Usually it is taking notes. Once you know where the improvement lives and what decides it, you can tell the two apart in about five seconds, and spend accordingly.
Matthew Kruczek is Managing Director at EY, leading Microsoft domain initiatives within Digital Engineering. Connect with Matthew on LinkedIn to discuss how to evaluate self-improving agent claims and build the memory and evaluation layers that make them real for your organization.
References
- Gartner. "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." June 25, 2025. gartner.com
- Shinn, et al. "Reflexion: Language Agents with Verbal Reinforcement Learning." arXiv:2303.11366. arxiv.org
- Fernando, et al. "Promptbreeder: Self-Referential Self-Improvement via Prompt Evolution." arXiv:2309.16797. arxiv.org
- Wang, et al. "Voyager: An Open-Ended Embodied Agent with Large Language Models." arXiv:2305.16291. arxiv.org
- Zelikman, et al. "STaR: Bootstrapping Reasoning With Reasoning." arXiv:2203.14465. arxiv.org
- Hu, Lu, and Clune. "Automated Design of Agentic Systems." arXiv:2408.08435. arxiv.org
- Zhang, et al. "Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents." 2025. arxiv.org
- Park, et al. "Generative Agents: Interactive Simulacra of Human Behavior." arXiv:2304.03442. arxiv.org