
If you only have a minute, here's what you need to know.
- RAG is not one technology. It is a family of at least five distinct architectures, each designed for a different class of query. Most enterprises treat it as a single pipeline and route everything through it.
- Naive vector RAG handles simple semantic lookups well. It fails on multi-hop reasoning, temporal queries, and anything requiring relational logic. On multi-hop benchmarks, static RAG scores around 34% accuracy while agentic RAG reaches 89%.
- The emerging production standard is hybrid routing: approximately 80% of enterprise queries go through fast vector search, 15% require graph-based reasoning, and 5% need full agentic treatment.
- Most RAG systems lose critical context before retrieval even begins. The way documents are chunked destroys the relationships between ideas, and most teams spend weeks choosing a vector database while spending minutes on their chunking strategy.
- Self-correcting RAG variants cut hallucination rates nearly in half. In clinical benchmarks, Self-RAG achieved a 5.8% hallucination rate versus 10.5% for the next best approach.
- RAG has a security surface most teams have not assessed. Adversarial attacks like BadRAG and TrojanRAG can manipulate retrieval results in ways invisible to end users.
Here is a question that reveals more about your AI architecture than any technical diagram: when your RAG system fails, do you know which type of query it failed on?
Most teams cannot answer that. They built one retrieval pipeline, pointed it at a vector store, and called it done. For simple semantic lookups, that works. "What is our remote work policy?" gets a clean, accurate answer.
But when a VP of Operations asks "How did the delay in the Project Atlas shipment affect our Q3 margins across APAC?", that same pipeline returns fragments of documents about Atlas and fragments about APAC, then hallucinates the causal relationship between them. The system retrieves relevant text. It cannot reason about the connections between that text. And nobody in the room understands why the answer is wrong, because it sounds fluent and cites real documents.
This is not a RAG failure. It is the wrong RAG for the query.
In my previous article on agentic memory, I made the point that RAG retrieves what you already knew while memory records what the agent has learned. That distinction still holds. But within RAG itself, there is a taxonomy that most enterprise leaders have never been introduced to. Understanding it is the difference between a retrieval system that works 80% of the time and one that works 95%.
The single-pipeline trap
Eighty-five percent of enterprise AI applications now use RAG as their foundational architecture. That adoption curve is remarkable. But the way most organizations implemented it, what researchers call Naive RAG, was the state of the art in 2023. Chunk your documents, embed them in a vector store, retrieve the top-k results at query time, and feed them to the model.
That approach has known failure modes. Low precision: chunks that match semantically but miss the actual intent. Low recall: relevant information that never surfaces because the chunking strategy split it across boundaries. And a fundamental inability to handle queries that require connecting information across multiple documents or reasoning about relationships.
34% accuracy on multi-hop reasoning for static RAG. 89% for agentic RAG on the same benchmarks.
— arXiv:2506.10408; Agentic RAG Survey, arXiv 2501.09136
The problem is not that teams chose vector RAG. The problem is that they chose it for everything. A global bank routing regulatory compliance queries through the same pipeline as "find me the latest quarterly report" is making an architectural mistake that no amount of prompt engineering can fix.
The RAG landscape has evolved through at least four generations since that first wave. Most enterprises are still on generation one.
The five architectures
There is no single "RAG solution," just as there is no single "database solution." Each architecture serves a different class of query, with different tradeoffs in cost, complexity, and accuracy.
Vector RAG · ~80% of queries
The workhorse for semantic similarity lookups
Embed documents as dense vectors, retrieve by similarity. Fast, well-understood, supported by every major framework. Excels at "What is our policy on X?" and "Find documents related to Y." Breaks on anything requiring relational reasoning or multi-hop logic.
Graph RAG · ~15% of queries
Deterministic traversal of entities and relationships
Stores entities and edges, not text. Traverses relationships for hallucination-resistant answers. The right architecture for regulatory exposure, supply chain tracing, and anything where "who approved what" matters more than "find similar documents."
Hybrid RAG · Production standard
Intelligent routing to the right backend per query
Not vector or graph, but a router that dispatches each query to the architecture best suited for it. Combines dense + sparse retrieval with Reciprocal Rank Fusion. Adoption tripled in Q1 2026. The emerging enterprise consensus.
Agentic RAG · ~5% of queries
Autonomous multi-step retrieval with query decomposition
An agent manages retrieval: decomposes queries, evaluates results, retrieves again if insufficient. Uses RAG Fusion and HyDE for query transformation. 89% accuracy on multi-hop vs. 34% for static. The cost is 3-8x per query.
Self-Correcting RAG · Layers on any type
Accept/refine/reject quality gates after retrieval
Adds a reflection loop: evaluate results, retry with a modified query, or reject entirely. Self-RAG cut hallucinations to 5.8% in clinical benchmarks (runner-up: 10.5%). Increasingly layered into every other architecture.
Vector RAG: where it breaks
Ask "Who approved the budget for Project Atlas, and does that person still have signing authority?" and vector search will return documents mentioning Atlas and documents mentioning signing authority. It will not traverse the chain of relationships that connects them. It guesses, fluently.
For the estimated 80% of enterprise queries that are straightforward semantic lookups, vector RAG is the right tool. The mistake is assuming the other 20% will quietly tolerate it.
Graph RAG: when relationships matter more than relevance
Microsoft's GraphRAG implementation demonstrated this at scale, but the initial cost was prohibitive: $20 to $500 to index a typical enterprise corpus. Their LazyGraphRAG variant, released in mid-2025, dropped that to under $5 by deferring community summarization to query time, adding 2 to 8 seconds of latency per query.
The most sophisticated graph implementations go further. They use community detection algorithms like Leiden to cluster related entities, apply feedback-weighted search so the graph learns which traversal paths produce good answers over time, and attach provenance metadata to every node and edge for compliance auditability. These are not research prototypes. They are production patterns in financial services and healthcare.
Fewer than 15% of enterprises have deployed graph-based retrieval in production, despite 40-60% accuracy improvements on complex relational queries.
— Industry analysis, TianPan.co, 2026
Hybrid RAG: the routing decision
The architecture decision is not "which RAG." It is "how do you route." The most effective hybrid systems combine dense embeddings with sparse keyword search (BM25) and use Reciprocal Rank Fusion to merge the results. The router can be a lightweight complexity classifier, a rules engine, or an LLM that evaluates intent before dispatching.
Some production systems use a tiered approach: classify query complexity first, then route simple queries to fast vector search and complex queries to graph or agentic pipelines. This alone can reduce retrieval costs by 30 to 50% on mixed workloads while improving accuracy on the hard queries.
Hybrid retrieval adoption tripled in Q1 2026, from 10.3% to 33.3% of enterprise respondents in VentureBeat's Pulse survey. The signal is clear: organizations that scaled past pilot are discovering that a single pipeline cannot serve production workloads.
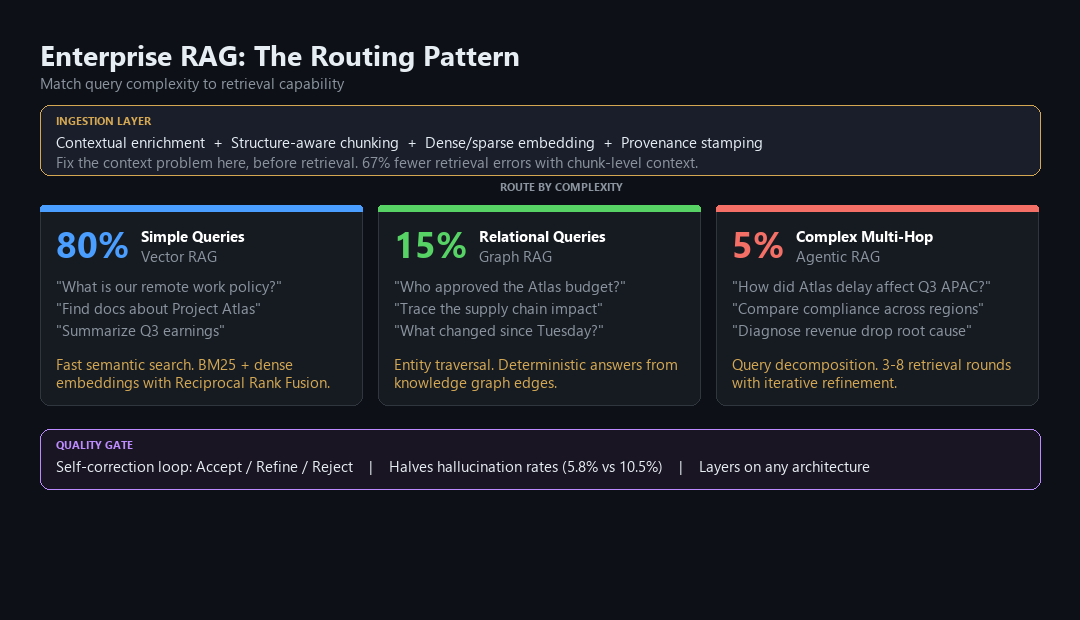
The 80/15/5 routing pattern. Match query complexity to retrieval capability.
Agentic RAG: query transformation changes the game
The most mature agentic implementations use query transformation before retrieval even begins. RAG Fusion generates multiple query variants from a single user question, retrieves against each variant, and merges the results. HyDE (Hypothetical Document Embeddings) has the model imagine what a perfect answer document would look like, then searches for real documents that match that hypothetical. These techniques reduce the brittleness that comes from assuming users always phrase their questions the way the documents phrase their answers.
The tradeoff is cost and latency. An agentic RAG pipeline may make 3 to 8 retrieval calls per query, each with its own LLM inference step. For the 5% of queries that genuinely need this treatment, the cost is justified. For the 80% that are simple lookups, it is waste.
This is why routing matters more than any single architecture choice.
Self-correcting RAG: quality gates that cut hallucinations in half
The most rigorous implementations use explicit quality gates with configurable thresholds. Each retrieved result passes through an accept/refine/reject evaluation. Results above the acceptance threshold go straight to generation. Results in the middle band trigger a refined retrieval attempt. Results below the rejection threshold are discarded entirely, and the system tells the user it does not have enough information to answer. This is more honest, and ultimately more valuable, than generating a fluent hallucination.
Self-RAG: 5.8% hallucination rate across 12 RAG variants on 250 clinical vignettes. Runner-up: 10.5%.
— MDPI Electronics 14(21):4227, October 2025
The pattern is converging: every serious production RAG system now includes some form of output verification before the response reaches the user.
The context problem hiding inside your chunks
There is a failure mode in RAG that predates retrieval entirely, and it may be doing more damage than choosing the wrong architecture.
When you chunk a document for embedding, you destroy context. A paragraph about "the revised terms" means nothing without knowing which contract it refers to. A table row showing "$4.2M" is useless without the column headers three pages earlier. A policy exception makes no sense without the policy it modifies. The moment you split a document into chunks, every chunk loses the context that made it meaningful.
Most teams spend weeks evaluating vector databases and minutes thinking about their chunking strategy. That priority is backwards. NVIDIA's benchmarks found up to a 9% recall gap between the best and worst chunking strategies across five document datasets. The vector database you choose matters far less than how you prepare what goes into it.
Fixed-Size Chunking
Split every N tokens with overlap. Simple and predictable. Also the worst at preserving meaning, because document structure does not respect token boundaries.
Structure-Aware Chunking
Respects the document's own organization: headings, sections, paragraph and table boundaries. Significantly better for policies, contracts, and technical documentation.
Semantic Chunking
Uses embedding similarity to find natural breakpoints. Adjacent sentences with high similarity stay together. Produces internally coherent chunks but requires an embedding pass.
None of these solve the context problem on their own. That requires a fourth technique.
67% reduction in retrieval errors when chunk-level context is prepended before embedding.
— Anthropic, "Introducing Contextual Retrieval," 2024
Contextual enrichment, introduced by Anthropic as Contextual Retrieval, addresses the root cause. Before embedding each chunk, an LLM prepends a short context snippet that situates the chunk within the broader document. "This chunk is from Section 4.2 of the Master Services Agreement between Acme Corp and Widget Inc., discussing liability limitations." That context becomes part of the embedding, so the chunk carries its own provenance into the vector store.
Combined with hybrid dense-plus-sparse retrieval and a reranking step, it represents the current best practice for corpus ingestion. If your RAG system was built before late 2024, it almost certainly does not do this. That is the single highest-value improvement most teams can make to an existing pipeline without changing their architecture.
Some production systems take this further with hierarchical summarization. The RAPTOR algorithm builds a tree of summaries at increasing levels of abstraction: individual chunks at the leaves, section summaries in the middle, document-level summaries at the root. Retrieval can then expand from a matched chunk to its parent summary for broader context, or narrow from a high-level match to specific supporting detail.
If your ingestion pipeline splits documents into chunks and embeds them without enrichment, your retrieval system is working with degraded inputs regardless of which architecture sits on top. Fix the context problem at the chunking layer before you invest in architectural upgrades.
The security surface nobody talks about
RAG has a security problem that most organizations have not assessed.
Adversarial retrieval attacks, specifically BadRAG and TrojanRAG, can manipulate what gets retrieved without altering the source documents. BadRAG injects adversarial passages into the corpus that are semantically proximate to common queries but contain manipulated content. TrojanRAG embeds trigger-activated payloads that activate only when specific query patterns are detected.
These are not theoretical. They have been demonstrated against production-grade vector stores. The fundamental vulnerability is that vector similarity search has no concept of document provenance or trustworthiness. A malicious passage that is semantically close to the query gets retrieved alongside legitimate content, and the model has no reliable way to distinguish between them.
The mitigation is not optional for regulated industries. Access controls on the retrieval corpus, provenance stamping on every ingested document (source, pipeline, timestamp), anomaly detection on retrieval patterns, and output verification layers that cross-check generated responses against trusted sources. Multi-tenant deployments need scope isolation at the retrieval layer, not just the application layer, so one user's queries never surface another tenant's documents.
What to do this week
Audit your chunking before your architecture. Before evaluating new retrieval frameworks, look at how your documents are being prepared. Are you using fixed-size chunking? Structure-aware? Does each chunk carry context about where it came from in the source document? If your ingestion pipeline has not changed since initial deployment, contextual enrichment is the single highest-ROI improvement you can make.
Classify your query traffic. Pull a sample of 200 to 500 queries from your production RAG system and categorize them: simple semantic lookup, relational reasoning, multi-hop, temporal. The distribution will tell you whether your current single-pipeline architecture is serving 95% of queries well or quietly failing on 20%.
Assess your multi-hop accuracy. Take the 10 hardest queries your users have submitted in the last month, the ones that require connecting information across multiple documents or reasoning about relationships between entities. Run them through your current pipeline and evaluate the answers against a human baseline. If accuracy drops below 60% on these queries, you have a graph RAG use case.
Add a self-correction loop. This is the second-highest-ROI change for most production systems. Before any RAG response reaches the user, add a quality gate: does the response actually follow from the retrieved content, or did the model extrapolate beyond what the documents support? Even a simple accept/refine/reject threshold can cut hallucination rates by 40 to 50%.
Run a retrieval security assessment. If your RAG system serves regulated workflows, test for adversarial retrieval manipulation. Verify that your corpus ingestion pipeline includes provenance tracking, that access controls are enforced at the retrieval layer, and that tenant isolation prevents cross-contamination in multi-user deployments.
The organizations treating RAG as a single technology are optimizing a pipeline. The organizations that understand the taxonomy are building an architecture. That distinction will separate the teams that scale from the teams that stall.
Matthew Kruczek is Managing Director at EY, leading Microsoft domain initiatives within Digital Engineering. Connect with Matthew on LinkedIn to discuss RAG architecture strategy for your enterprise AI program.
References
- arXiv. "Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG." January 2025. arxiv.org
- arXiv. "Agentic Retrieval with LLMs for Multi-Hop Question Answering." 2025. arxiv.org
- VentureBeat. "Enterprise RAG rebuild: hybrid retrieval adoption tripled in Q1 2026." venturebeat.com
- MDPI Electronics. "Evaluating RAG Variants for Clinical Decision Support." 14(21):4227, October 2025. mdpi.com
- Anthropic. "Introducing Contextual Retrieval." September 2024. anthropic.com
- Microsoft Research. "GraphRAG and LazyGraphRAG." 2025.
- TianPan.co. "GraphRAG vs. Vector RAG: The Architecture Decision Teams Make Too Late." April 2026. tianpan.co
- CMARIX. "RAG & AI Trust Statistics 2026." cmarix.com
- Stack Overflow. "Breaking up is hard to do: Chunking in RAG applications." December 2024. stackoverflow.blog
- NCBI. "A self-correcting Agentic Graph RAG for clinical decision support." 2026. ncbi.nlm.nih.gov
- RAGFlow. "From RAG to Context: A 2025 Year-End Review." ragflow.io


