Executive read
If you only have a minute, here's what you need to know.
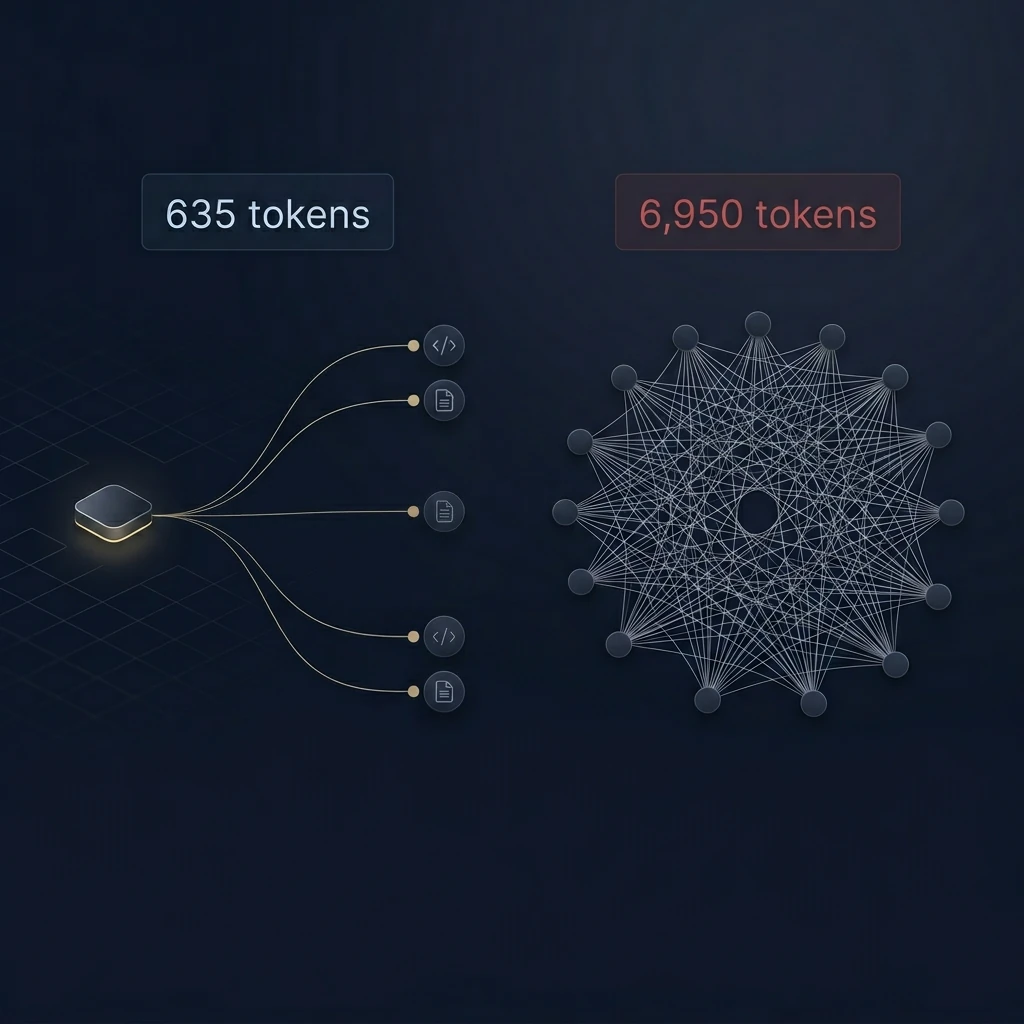
- Every time your AI agent starts a session, it reads a full inventory of every tool available to it before doing any actual work. For a typical developer setup connecting to two popular services, that inventory consumes nearly 7,000 tokens. A hub pattern cuts that to 635. Every session. Every day.
- The savings compound at team scale. A team of 50 running Claude sessions daily saves over 300,000 tokens per day just from startup overhead, before a single useful thing is accomplished.
- The hub also eliminates extra back-and-forth between your AI and its tools. Multi-step tasks that normally require two or three separate exchanges collapse into one. Less context accumulation, fewer interruptions, faster results.
- A post by Jeremy Lowin introduced this architecture. I built it, ran the benchmarks, and found a few corrections to make it actually work. The source code is open at github.com/MCKRUZ/mcp-experiment.
- The pattern is worth understanding now. As enterprise AI deployments grow from handfuls of tools to hundreds, this kind of architecture becomes less of an optimization and more of a requirement. (It's one piece of a three-layer architecture that also includes Agent Skills and A2A.)
In January I published a whitepaper on progressive disclosure for MCP servers — the idea that AI agents shouldn't be handed a 500-page manual every time they sit down to work. Instead of loading every available tool definition upfront, agents should discover tools on demand, fetching details only when needed. I documented five patterns doing this in production and made the case that the approach wasn't optional at enterprise scale.
What I didn't have was my own data from actually building one.
Then Jeremy Lowin published a technical blog post introducing FastMCP 3.1's CodeMode, a new pattern that puts this idea into practice directly in the framework. I built the hub he described, ran benchmarks against real services, hit a few places where the implementation details had shifted from the documentation, and came out with numbers worth sharing.
The problem, and how the hub solves it
Every MCP server your team connects to is made up of one or more tools. Take GitHub as an example: the GitHub MCP server exposes 26 tools, one to search repositories, one to create an issue, one to list pull requests, one to read a file, and so on. Each tool comes with a full specification describing what it does, what inputs it needs, and what it returns. Here's what that looks like for a single tool:
create_issue — Creates a new issue in a GitHub repository. Requires: repository owner (text), repository name (text), issue title (text). Optional: body text, assignees, labels, milestone. Returns: the created issue with its ID, URL, and status.
That's one tool out of 26 on GitHub alone. For this experiment I connected two MCP servers:
| MCP Server | What it does | Tools exposed |
|---|---|---|
| Context7 | Gives the AI access to current technical library documentation | 2 |
| GitHub | Connects the AI to repositories, issues, pull requests, files, and workflow runs | 26 |
| Total | 28 |
The problem: the AI reads the full specification for every one of those 28 tools at the start of every session, whether it ends up using them or not. Think of it like requiring an employee to read the entire company policy manual before answering every email. Most of it is irrelevant. All of it consumes time and mental bandwidth that could go toward the actual work.
For these two MCP servers alone, that inventory runs to nearly 7,000 tokens before a single useful thing happens. Multiply that across a growing list of integrations and a team running hundreds of AI sessions per week.
The hub sits in front of both MCP servers and exposes just 3 tools of its own:
- Search — find tools across all connected servers by describing what you need
- Get details — fetch the full specification for a specific tool, on demand
- Execute — run a multi-step sequence and return only the final result
All 28 tools remain fully accessible behind the hub. The AI just doesn't load their blueprints until it needs them. Intermediate steps, looking things up, chaining one result into the next query, happen inside the hub. The AI sees the final answer, not the working notes.
It's the same principle behind good executive briefings: you don't hand the CEO a raw data dump. You surface what's relevant, on demand, and present a conclusion.
The benchmark results
I measured two things: how many tokens the AI consumes before starting any task, and how many back-and-forth exchanges a typical multi-step task requires.
Token cost at session start
Without the hub, the AI loads a complete blueprint for every tool it has access to before doing any work. The hub replaces all of that with three simple doorways: search, get details, execute. The actual tools still exist; the AI just doesn't read their blueprints until it needs them.
| What the AI loads at startup | Tokens consumed |
|---|---|
| Hub (3 doorways, all 28 tools accessible behind them) | 635 |
| Both services connected directly (28 full tool blueprints) | 6,950 |
| Savings | 6,315 tokens — 91% reduction |
The 28 tools don't disappear. They're still available through the hub on demand. The AI just isn't forced to read every blueprint before starting.
At team scale, the math gets interesting. Fifty developers each running ten AI sessions per day generates roughly 315,000 tokens of pure overhead daily under the direct approach. The hub cuts that to under 32,000.
Interaction efficiency
| Approach | AI exchanges required | Time |
|---|---|---|
| Hub — one combined execution | 1 | 1,339ms |
| Direct — two separate calls | 2 | 785ms |
The hub is slower by the clock on a two-step task. It completes the work in one AI exchange instead of two. For simple lookups, direct is faster and that's the right choice. For agents working through complex workflows, where each exchange adds to an accumulating context and introduces another opportunity for drift, fewer exchanges is the better outcome.
The rough threshold: three or more chained steps and the hub wins on both efficiency and quality. Two steps or fewer, direct is fine.
What I found building it
Jeremy Lowin's post introduced the architecture clearly. A few implementation details had shifted by the time I built it, which is worth noting for anyone following his guide.
The module path in the code changed from what the post shows. The way you apply the transformation also changed. There are two methods available and only one of them produces a server the framework can actually run. I hit both of these, sorted them out, and documented the corrections in the repository.
The execution environment the hub uses to chain tool calls is also more constrained than it appears. Standard programming utilities most developers would reach for aren't available inside it. That's fine in practice, the hub handles the translation automatically, but it's counterintuitive if you're used to full scripting environments.
None of this reflects poorly on the underlying work. The architecture is sound. Experimental releases move fast and documentation trails the code. The corrections are in the repo for anyone who runs into the same issues.
What this means at the executive level
The deeper point isn't about token counts. It's about architecture.
Most enterprise AI deployments today connect agents directly to tools: a growing list of services, APIs, and data sources, each one adding to the overhead every session carries. This works at small scale. It starts to break as the toolset grows.
The hub pattern solves this structurally. The AI's startup cost stays fixed regardless of how many services sit behind the hub. Adding a new integration doesn't increase the tax every session pays. The AI's working memory is available for actual work rather than inventory management.
For organizations planning their AI infrastructure, this is the kind of architectural decision that's easy to make now and painful to retrofit later. The token savings are real and measurable today. The scalability benefit is what matters at 12 and 24 months.
The source code, tests, and benchmark scripts are at github.com/MCKRUZ/mcp-experiment. Your engineering team can have a version running in an afternoon, and the benchmark tooling makes it straightforward to measure the impact against your own setup.
References
- Kruczek, M. "Progressive Disclosure for MCP Servers: A Design Pattern for Scalable AI Tool Integration." January 27, 2026. matthewkruczek.ai
- Lowin, J. "FastMCP 3.1 — Code Mode." March 2026. jlowin.dev
- Kruczek, M. mcp-experiment: FastMCP 3.1 CodeMode Hub. 2026. github.com/MCKRUZ/mcp-experiment
- Anthropic. "Code execution with MCP: Building more efficient agents." November 4, 2025. anthropic.com
Matthew Kruczek is Managing Director at EY, leading Microsoft domain initiatives within Digital Engineering. Connect with Matthew on LinkedIn to discuss AI architecture and cost optimization strategies for your organization.
