If you only have a minute, here is what you need to know.
- Organizations deploying AI coding tools to development teams without token management training are repeating the cloud sprawl mistake of 2010 to 2015. The same pattern, different resource. And the bills are arriving faster this time.
- A single developer without token discipline can consume ten times or more tokens than a trained one for the same output. Multiply that across a 200-person engineering organization paying per-API-token rates, and the annual waste reaches six figures before anyone notices.
- With a Claude MAX subscription and disciplined context management, I build production enterprise software for $200 per month. Not because the tools are cheap. Because the approach is intentional.
- Open source tools like LangFuse, LiteLLM, and OpenTelemetry's GenAI semantic conventions give you visibility into token consumption patterns before costs spiral. You do not need a vendor platform to start monitoring.
- Token literacy is not an advanced skill. It is table stakes for any engineering organization deploying AI tools at scale. The organizations that treat it as optional will pay the tax. The ones that invest in training will not.
Here is a scenario that is playing out at enterprises right now. An engineering leader approves an AI coding tool rollout. Licenses go to 200 developers. Three months later, the finance team flags an API line item that has gone from $5,000 a month to $85,000 a month. Nobody can explain why. Nobody was watching.
This is the token tax: the cost organizations pay when they deploy AI tools without teaching developers how those tools actually consume resources. It is not a technology problem. It is a training problem. And for most enterprises, it is entirely avoidable.
We have seen this movie before
Between 2010 and 2015, enterprises experienced the first wave of cloud cost shock. The pattern was consistent. IT leadership approved cloud adoption. Development teams received AWS or Azure accounts. Nobody set guardrails. Nobody tagged resources. Nobody established budgets or alerts.
What followed was predictable. Developers spun up compute instances for testing and forgot to shut them down. Teams provisioned oversized VMs because "it is just cloud, we can scale down later" and never did. Storage volumes accumulated because deleting things felt risky. By 2014, surveys showed that the average enterprise was wasting 30 to 35 percent of its cloud spend on idle or underutilized resources.
The industry responded with an entire discipline: FinOps. Organizations hired cloud economists. Vendors built cost management platforms. Tagging policies became mandatory. Reserved instance planning became a quarterly exercise. The message was clear: the cloud is not expensive, but using it without discipline is.
AI tokens are following the same trajectory, compressed into a shorter timeline. The resource is different, but the organizational failure is identical: deploying a consumption-based technology without training the people who consume it.
There is one critical difference. Cloud waste accumulated over months. Token waste accumulates in minutes. A developer who pastes an entire codebase into a prompt, asks a vague question, gets an unsatisfying answer, and tries again with the same approach can burn through thousands of dollars in a single afternoon. With cloud, the unused EC2 instance sat there quietly running up a tab. With tokens, the waste is active. Every keystroke in an untrained workflow costs real money.
The $200-per-month enterprise developer
I want to put a concrete number against this to make the contrast visible.
I build enterprise software using a Claude MAX subscription. That is $200 per month, flat. With that subscription and a disciplined approach to context management, I have built and continue to develop a production-grade agent harness that includes a full skills system, MCP server and client implementations, a tiered context engine, RAG pipelines, agent-to-agent communication, and observability infrastructure. Clean Architecture, CQRS, the full stack. Enterprise-grade code, not prototypes.
$200 per month.
Meanwhile, I talk to engineering leaders whose teams are spending $15,000 to $30,000 per month on API tokens for work that produces less output than what I ship on a fixed-cost subscription. The difference is not the tool. The difference is not the model. The difference is how you use the context window.
That gap, the factor of 10x or more between a trained developer's token efficiency and an untrained one, is where the money lives. And in most organizations, nobody is measuring it.
Why tokens get wasted
Token waste is not random. It follows patterns, and nearly all of them trace back to developers who were never taught how large language models actually process input.
The context dump
The most expensive anti-pattern is treating the AI like a search engine with infinite memory. A developer pastes an entire 2,000-line file into the prompt, then asks "what is wrong with this code?" The model processes every token of that file, charges for the input, generates a response that addresses maybe 30 lines, and the developer has paid for 1,970 lines of irrelevant context.
This is not a marginal problem. In my testing, 60 to 75 percent of the typical context window is consumed by information the model does not need in raw form. Raw build logs? Dumped in wholesale. Five hundred lines of git history? Dumped in. A single research task can consume 45 percent of your context window on raw command output alone, leaving barely enough room for the actual work.
Trained developers isolate the relevant code, describe the expected versus actual behavior, and provide only the context the model needs. The same answer, one-tenth the tokens.
The retry loop
When an untrained developer gets an unsatisfying response, the instinct is to try again with the same prompt or a slight variation. Each retry re-processes the entire conversation history. By the fifth attempt, the developer has paid for the original prompt five times over, with compounding context from prior failed responses inflating each subsequent call.
Trained developers reset the context, refine the prompt based on what went wrong, and start a clean conversation. They treat failed prompts as signal, not as something to power through.
No progressive disclosure
Most developers load everything upfront because they do not know there is an alternative. They include every file, every type definition, every configuration detail in the initial prompt because they are not sure what the model will need.
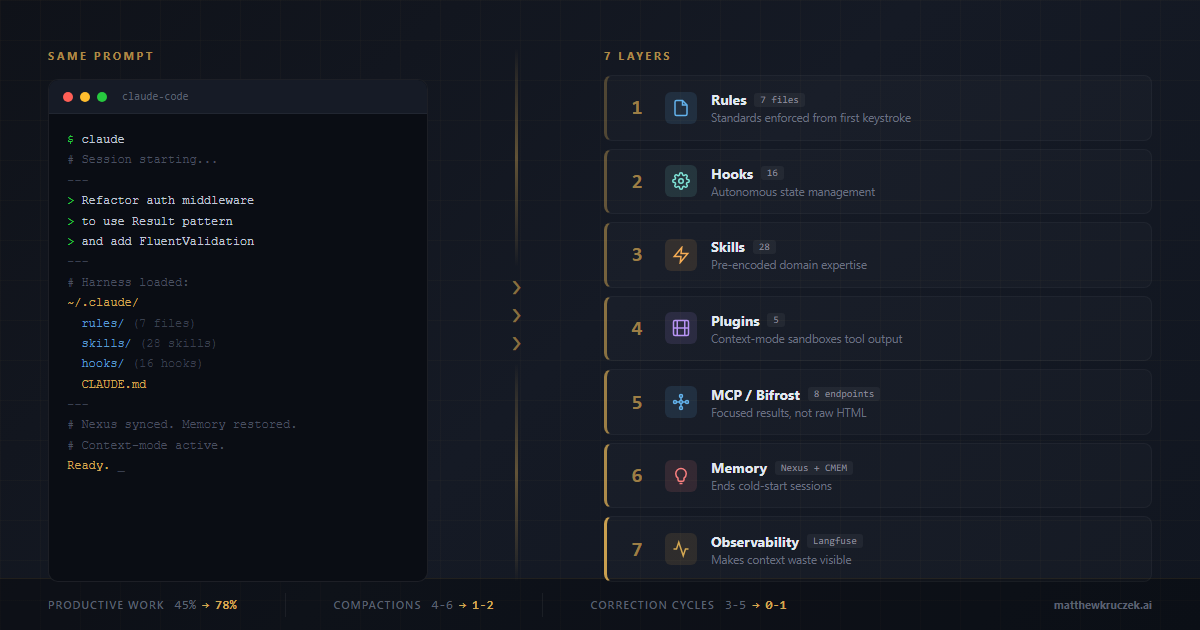
In the agent harness I have built, context loading follows a three-tier progressive disclosure model. Tier 1 is an index card: name, description, and tags at roughly 100 tokens. Tier 2 is a folder: full instructions and tool declarations at roughly 5,000 tokens. Tier 3 is the filing cabinet: scripts, references, and templates at unbounded size. The system only loads deeper tiers when it determines the shallower context is insufficient.
This is not a minor optimization. It is the difference between burning 50,000 tokens per turn and burning 2,000. Over a day of active development, that difference compounds into hundreds of dollars on per-token pricing.
MCP and tool sprawl
As organizations adopt agentic AI, a new category of waste is emerging: tool definition bloat. Every MCP server, every skill, every tool definition consumes tokens just by existing in the context window. A team that connects 20 MCP servers because "more tools means more capability" may be burning tens of thousands of tokens per conversation on tool definitions the model never uses. At enterprise scale, with 400 tools registered, the definitions alone consume over 400,000 tokens, often exceeding the entire context window before any work begins.
The problem is not just cost. It is also quality. Models, like humans, make worse decisions when presented with too many options. Decision fatigue is real for AI agents. Fewer, well-chosen tools produce better results at lower cost than a sprawling registry of every capability someone thought might be useful.
The compaction tax
When a context window fills up, the AI has to compact: summarize and discard older conversation history to make room. Every compaction loses conversational state. Every lost state means the developer re-explains context, re-explores files, and re-orients the model on decisions already made. This is the hidden compounding cost that most teams never see.
In default configurations without proper context management, sessions hit four to six compactions per session. Each compaction is not just a performance hit. It is a token multiplier, because the developer pays again for every piece of context the model forgot. With proper harness configuration, rules files, and progressive loading, compactions drop to one or two per session. The token savings compound with every compaction avoided.
No visibility
You cannot manage what you cannot see. Most development teams using AI tools have zero visibility into per-developer token consumption, per-project token allocation, or cost-per-output metrics. They get one aggregated bill at the end of the month and have no way to attribute costs to teams, projects, or individual usage patterns.
Imagine running a cloud environment where you could not see which team was using which resources. That was 2011. We solved it with tagging, cost allocation, and resource monitoring. The same tooling needs to exist for token consumption, and the good news is that open source options are already available.
Open source tools that give you visibility
You do not need to buy a vendor platform to start understanding your token consumption. The open source ecosystem has matured enough to give you real monitoring and cost attribution today.
LangFuse
LangFuse is a fully open source LLM observability platform that you can self-host. It captures traces, token counts, latency, cost, and quality scores across every LLM interaction. You can tag traces by user, project, or environment and build dashboards that show exactly where your tokens are going. If you need one tool to start with, this is the one. Deploy it on your own infrastructure, point your LLM calls through it, and within a week you will have data that will surprise you.
LiteLLM
LiteLLM is an open source proxy that sits between your application code and any LLM provider. It provides a unified API interface across OpenAI, Anthropic, Azure, and dozens of other providers, with built-in cost tracking, rate limiting, and budget management. You can set per-team or per-project token budgets, get alerts when consumption exceeds thresholds, and route requests to different models based on cost or performance requirements. Think of it as the API gateway layer that brings cloud-style governance to LLM consumption.
OpenTelemetry GenAI semantic conventions
If your organization already runs OpenTelemetry for application observability, you are closer to token monitoring than you think. The GenAI semantic conventions define standardized attributes for LLM operations: model name, token counts (input, output, total), operation type, and response metadata. Instrument your LLM client calls with these conventions and your existing Grafana, Datadog, or New Relic dashboards can show token consumption alongside your other application metrics. No new platform required.
Helicone
Helicone offers an open source gateway that logs every LLM request, tracks costs, and provides analytics on usage patterns. It requires a single-line code change (a proxy URL swap) and immediately starts capturing data. The open source version covers the core logging and cost tracking. If you want a quick win to demonstrate the problem to leadership, Helicone can be running in production within an hour.
Building token-aware systems
Monitoring tells you where the waste is. Architecture prevents it from happening in the first place. The most effective approach I have found combines three ideas: budget-aware context assembly, progressive disclosure, and structured prompt patterns.
Budget-aware context assembly
In my harness, every conversation turn runs through a context budget tracker that monitors token allocation across four categories: system prompt, active skills, tools, and conversation history. When budget runs low, the system automatically falls back from full skill instructions to lightweight summaries. The developer never has to think about it. The system self-regulates.
This is not a theoretical optimization. In a benchmark I ran across five production scenarios, progressive disclosure of tool definitions produced an 85 to 100x token reduction compared to flat-loading everything upfront, while simultaneously improving agent accuracy. The math is stark: a flat MCP configuration with 400 tools consumes over 400,000 tokens before any work begins, often exceeding the entire context window. Progressive disclosure loads only what the current task requires.
The token math across the full harness tells the story. Rules files cost 3,000 tokens upfront but save 15,000 to 20,000. Automation hooks cost 2,000 but save 25,000 to 35,000 by keeping raw output out of the context window. Skills cost 2,000 but save 10,000 to 15,000 per invocation by loading instructions on demand rather than permanently. Context-mode processing costs 500 tokens but saves 30,000 to 50,000 by summarizing tool output before it enters the conversation. Every layer is a deliberate investment that pays for itself many times over.
The principle applies to any team building agentic AI applications: treat the context window as a budget, not a dumping ground. Allocate tokens intentionally across categories. Degrade gracefully when the budget is constrained.
Structured prompt engineering
The single highest-leverage practice is replacing conversational prompts with structured ones. Instead of "help me fix this authentication bug," a structured prompt looks like this:
## Task
Fix the JWT validation failure in the authentication middleware.
## Context
- File: src/Auth/JwtMiddleware.cs, lines 45-62
- Symptom: ValidateLifetime returns false for tokens within expiry
- ClockSkew is set to TimeSpan.Zero
## Constraints
- Must maintain backward compatibility with existing token format
- Cannot change the signing key rotation scheduleThe structured version uses fewer tokens in the prompt, produces a more targeted response (which uses fewer output tokens), and rarely needs a retry. The total token cost for a structured interaction is typically 20 to 30 percent of a conversational one.
Agent rules files: preloading efficient context
One pattern I rely on heavily is maintaining a set of agent rules files that preload project-specific context into every conversation. These files tell the AI what the project is, what conventions to follow, what patterns to use, and what to avoid. The upfront token investment (roughly 3,000 to 5,000 tokens) eliminates entire categories of wasteful back-and-forth that would otherwise consume 20,000 to 50,000 tokens in clarifying questions and wrong-direction attempts.
The data backs this up. In my harness, sessions with proper rules files run at a 70 to 80 percent productive work ratio compared to roughly 45 percent in default configurations. Compactions (the expensive operation where the AI summarizes and discards conversation history) drop from four to six per session to one or two. Rules cost 3,000 tokens upfront but save 15,000 to 20,000 tokens per session in eliminated back-and-forth.
Think of it as configuration over conversation. A well-maintained rules file is cheaper than explaining your project from scratch every session. I wrote about this approach in more detail in the context engineering piece, and the harness implementation includes a TOON pattern that reduced token consumption by 85 percent in structured data exchanges.
Eight practices that cut token waste
If you are an engineering leader deploying AI tools to your team, these are the practices that produce measurable results. They are ordered by impact, not difficulty.
1. Monitor before you optimize. Deploy LangFuse or Helicone before doing anything else. You cannot set targets without a baseline. Give it two weeks to collect data, then look at the per-developer distribution. You will find that your top five percent of token consumers are likely responsible for 40 to 50 percent of total spend.
2. Set per-project token budgets. Use LiteLLM or a similar proxy to set hard limits by team or project. Not to punish anyone, but to create the forcing function that makes developers think about consumption. Cloud teams did this with AWS budgets a decade ago. Same principle applies.
3. Train on context window mechanics. Your developers need to understand, at a basic level, how input tokens, output tokens, and context windows work. This is not a deep technical seminar. It is a 90-minute workshop that covers: how tokens map to text, why context length matters, what happens when you exceed the window, and how pricing scales with input and output. Most developers have never been taught this.
4. Teach structured prompting. Replace "ask the AI a question" with a structured prompt template. Task, context, constraints. Invest one afternoon in building a prompt template library for your most common development tasks: code review, bug investigation, test generation, documentation. The template enforces discipline without requiring the developer to remember it.
5. Implement progressive context loading. Whether you build a full tiered system like the one in my harness or simply adopt the practice of starting with minimal context and adding more only when needed, progressive loading is the architectural pattern that produces the largest cost reduction. Start small. Add context when the model asks for it. Never dump everything upfront.
6. Simplify your tooling surface. More tools does not mean more capability. It means more tokens consumed on tool definitions before any work begins. Vercel demonstrated this when they cut their agent's tool count from 15 to 2 and hit 100 percent accuracy, with token usage dropping 37 percent and speed improving 3.5x. Manus achieved a 10x cost reduction through pure infrastructure simplification. The lesson is counterintuitive but consistent: fewer, sharper tools outperform bloated toolkits every time.
7. Reset, do not retry. Teach developers to start fresh conversations when an approach is not working instead of continuing to iterate in the same context. Every message in a conversation carries the full history. By message ten, you are paying for message one through nine again on every turn. A clean start with a refined prompt is almost always cheaper than a sixth attempt in a bloated context.
8. Maintain agent rules files. Invest in a project-level rules file that preloads conventions, architecture decisions, and coding standards into every AI session. The 30 minutes it takes to write and maintain eliminates hours of wasteful context-setting conversations across the team. One file, maintained by the tech lead, used by every developer on the project. The ROI is immediate and compounding.
The FinOps parallel is exact
Every objection I hear about token management is one I heard about cloud cost management ten years ago.
"Developers should not have to think about cost, that slows them down." They said the same thing about cloud resources. The organizations that accepted that argument spent millions on idle infrastructure. The ones that built cost awareness into the development culture saved that money without slowing anyone down.
"We will optimize later, right now we need to move fast." Later never comes. By the time "later" arrives, the consumption patterns are entrenched, the budgets are locked in, and the conversation shifts from "how do we optimize" to "how do we justify this line item."
"Our vendor handles optimization for us." Your vendor is incentivized to sell you tokens, not to help you use fewer of them. The same was true of cloud providers. AWS was happy to let you run oversized instances. The optimization tooling came from third parties and internal teams, not from the provider.
The organizations that learned from the cloud era are applying those lessons to AI. The ones that did not are paying the token tax. And unlike cloud waste, where an idle VM costs you $50 a month, a single untrained developer with API access can generate thousands of dollars in waste per week.
What to do this week
Audit your current token spend. Pull the last 90 days of LLM API invoices. Break them down by team if you can, by project if you cannot. Compare month-over-month growth. If the line is steeper than your headcount growth, you have a training problem.
Deploy one monitoring tool. Pick LangFuse, Helicone, or LiteLLM and deploy it against your highest-volume project. Do not try to instrument everything at once. One project, one week of data, one dashboard. That is enough to demonstrate the distribution to your leadership team.
Schedule a 90-minute workshop. Cover how tokens work, why they cost money, and three practices that reduce consumption (structured prompts, progressive context, clean resets). Make it mandatory for any developer with API access. This single investment will pay for itself within the first month.
Write one agent rules file. Pick your highest-cost project and invest 30 minutes in a context file that describes the project, its conventions, and its patterns. Share it with the team. Watch the per-developer token consumption on that project drop within the first week.
The token tax is real, and it is growing. But unlike actual taxes, this one is entirely optional. The organizations that invest in token literacy, monitoring, and architectural discipline will build more with less. The ones that do not will continue to wonder why their AI bill keeps climbing while their output stays flat.
Matthew Kruczek is Managing Director at EY, leading Microsoft domain initiatives within Digital Engineering. Connect with Matthew on LinkedIn to discuss token economics, AI development practices, and developer enablement for your enterprise.
References
- Flexera. "State of the Cloud Report." Average enterprise cloud waste estimated at 30-35% of total spend (2014-2016 peak). flexera.com
- FinOps Foundation. "What is FinOps?" Cloud financial management as a cultural practice, not a tooling solution. finops.org
- LangFuse. Open source LLM engineering platform for traces, evaluations, and cost analytics. langfuse.com
- LiteLLM. Open source LLM proxy with unified API, cost tracking, and budget management. github.com/BerriAI/litellm
- OpenTelemetry. GenAI Semantic Conventions for standardized LLM observability. opentelemetry.io
- Kruczek, M. "Same Prompt, Different Results. Your Agent Harness Is the Multiplier." Harness architecture and tiered context loading. matthewkruczek.ai
- Kruczek, M. "How We Cut AI Token Costs 85% with One Design Pattern." TOON pattern for structured data token optimization. matthewkruczek.ai
- Kruczek, M. "Progressive Disclosure MCP: 85x Token Savings Benchmark." Benchmarked progressive disclosure against flat tool loading across five production scenarios. matthewkruczek.ai
- Kruczek, M. "Agent Harnesses Need Fewer Layers, Not More." Vercel and Manus case studies on simplification as the primary optimization lever. matthewkruczek.ai